
Contents
Amazon RDS
Amazon RDS(Relational Database Service)ではスナップショットを他アカウントと共有できます。
例えば他部署でデータベースのコピーが必要だったり、新たに作成するアカウントへデータベースを移行したいような場合は、スナップショットを共有し、共有したアカウントでスナップショットからデータベースを復元するといった運用が可能です。
スナップショットを共有するには、対象のAWSアカウントへスナップショットへのアクセスを許可します。
なお、自動バックアップのスナップショットは他アカウントとの共有はできません。自動バックアップのスナップショットをコピーするか、手動のスナップショットを共有します。
また、データベースが暗号化されている場合は、作成するスナップショットも暗号化されています。
暗号化されたスナップショットを共有する場合は、共有先のアカウントへKMS(Key Management Service)の暗号化キーの使用を許可する必要があります。
Amazon RDS データベースやAmazon Auroraデータベースクラスタに対して「削除保護」機能を有効にすると、設定されたデータベースは削除ができなくなります。これにより、ユーザの操作ミスによる意図しない削除操作からデータベースを保護することができます。

Amazon RDSでは、RR(リードレプリカ)という、参照専用のデータベースとして動作するレプリカ(複製)を作ることができます。データベースの参照時にかかる負荷が高い場合、RRを最大15台スケールアウト(処理台数の追加)し、参照時の負荷を分散できます。

また、データベースのインスタンスクラス(EC2における”インスタンスタイプ”と同等)を変更することにより、スケールアップ(拡張)、スケールダウン(縮小)も柔軟に行うことができます。
スケールアップ/ダウンではインスタンスの性能(CPUやメモリなど)が変動しますが、性能の良いインスタンスはその分料金もかかります。
負荷分散を行うことをスケールアウト(Scale out)、データベースインスタンスを拡張することをスケールアップ(Scale up)といいます。いずれも、データベースアクセスのパフォーマンス改善に機能します。
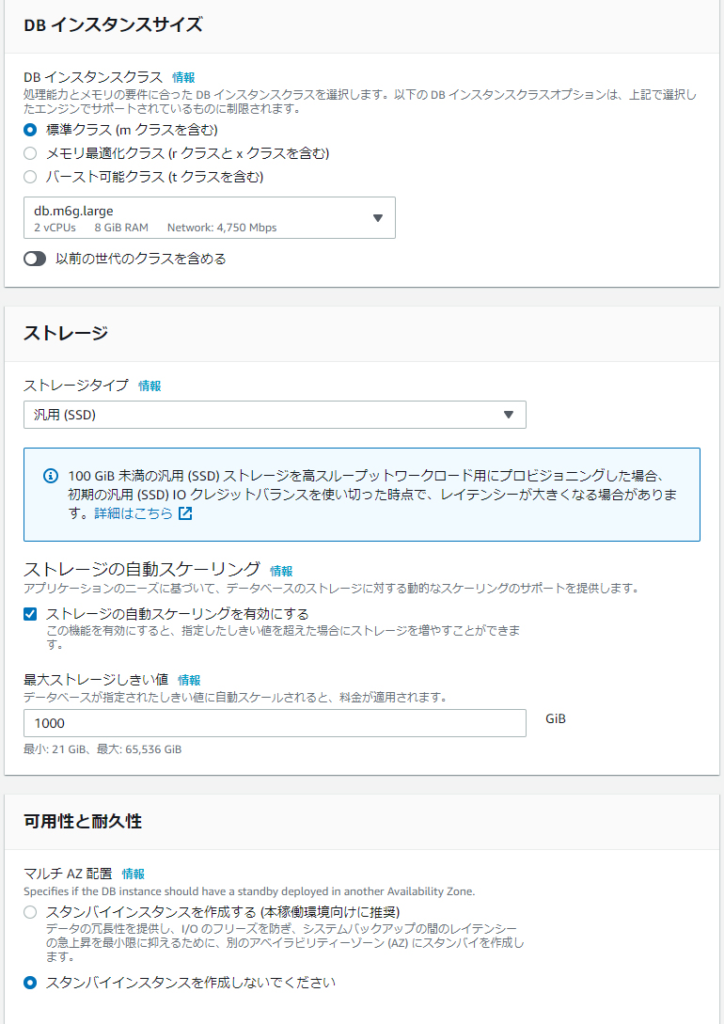
リードレプリカ(RR)を作成する際には、インスタンスクラスやストレージタイプ、マルチAZのほか、サブネットの設定、自動スケーリングの有無、認証方法などの設定を行えます。
Amazon RDSでは、AZ(Availability Zone)を超えたデプロイメント(マルチAZ)で、自動レプリケーション+フェイルオーバーを実現できます。

プライマリDBインスタンスに障害が発生しても、スタンバイDBインスタンスがプライマリDBインスタンスに切り替わり、運用を継続することができます。
フェイルオーバーは以下のタイミングで実行されます:
– プライマリAZの障害
– プライマリDBインスタンスへのネットワーク接続不可
– プライマリDBインスタンスの障害
Amazon RDSは、データベースインスタンスを暗号化することができます。
また、データベースインスタンスの暗号化を行うと、バックアップやスナップショット、ログ、RR(リードレプリカ:参照専用のデータベースレプリカ)へも暗号化が行われます。
暗号化を行う場合はデータベースの作成時に指定し、作成した後に暗号を有効化することはできません。

暗号化されていないデータベースインスタンスを暗号化したい場合は、対象のインスタンスのスナップショットを作成し、スナップショットをコピーする際に暗号化を有効にします。暗号化されたスナップショットを基にデータベースインスタンスを復元すると、暗号化されたデータベースインスタンスが新規に構築されます。
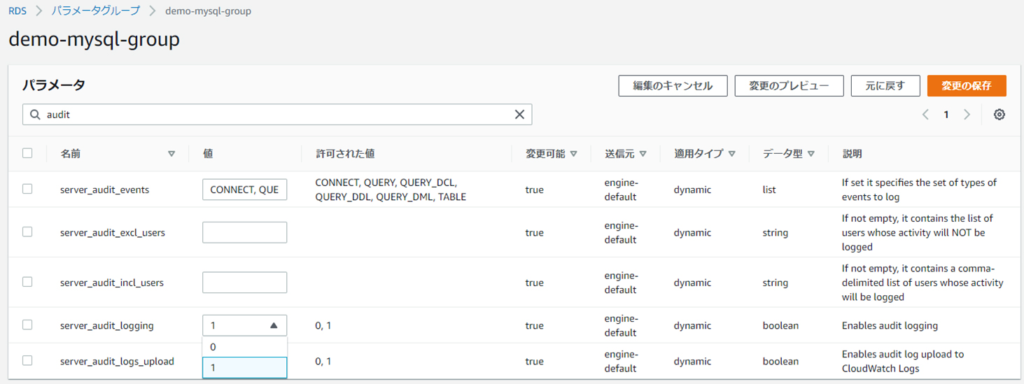
Amazon RDSにおいてタイムゾーンや最大接続数、監査ログの有効化などデータベースの設定を変更したい場合は、「DBパラメータグループ(DBクラスターパラメータグループ)」または「オプショングループ」で定義します。
DBパラメータグループ、オプショングループはDBエンジンごとに作成するパラメータまたはオプションの定義グループで、作成後は複数のデータベース(またはデータベースクラスター)へアタッチできます。
なお、設定可能な項目や、設定する項目名はデータベースエンジンごとに異なります。例えばタイムゾーンを変更する場合、Oracleデータベースはオプショングループから、その他のデータベースエンジンはパラメータグループから変更するなどの細かな差異があります。
以下はクラスターパラメータグループで監査ログを有効化する際の設定例です(Aurora MySQL 8.0)。
Amazon Auroraは、Amazonが設計・開発したMySQL/PostgreSQL互換のデータベースエンジンです。フルマネージド型サービスであるAmazon RDS(Relational Database Service)で利用可能なデータベースエンジンですので、データベースのスケーリング(拡張、縮小)、高可用性、バックアップ、OS/データベースソフトウェアへのパッチ、サーバーの電源やメンテナンスなどはRDS(AWS)によって管理されます。
Auroraを利用した際の構成例は以下の通りです。

Auroraには以下のような特徴があります。
(1) データベースインスタンスとストレージが分離したアーキテクチャ
データベースインスタンスだけを必要に応じて増減できます。手動でのデータベース管理が不要なサーバーレス構成や、最大15台のレプリカ(複製)インスタンスなど柔軟な構成が可能です。
(2) 複数のデータコピーと自動修復機能などによるストレージの高い耐障害性
ストレージは、デフォルトで3つのAZに2つずつ(計6つ)のデータコピーが作成されます。これらのストレージは「クラスタボリューム」というクラスタ構成で管理されます。
Auroraのクラスタボリューム内のストレージは互いに監視しあっており、データの破損が発生しても自動で検出、修復します。
Auroraにはデータベースのクローン(複製)を作成する機能があります。クローンは「Copy-on-Write」という技術で作成されます。Copy-on-Writeは、データの複製時にコピーしたと見せかけて、実際は複製元のデータを参照します。
複製元または複製先のデータの更新時に対象のデータをコピーして、それ以降はコピーしたデータにアクセスします。更新したデータ以外は、複製元のデータを参照するのでストレージ容量の節約になります。また、クローンの作成時にデータのコピーが発生しないので、スナップショットの取得/復元やデータベースのエクスポート/インポートするよりも複製を高速に作成できます。
Aurora ServerlessはDBインスタンスの負荷状況に応じて、自動的にDBインスタンスの起動、停止、スケールアップ/スケールダウンを実施する機能です。
通常のAuroraではDBインスタンス作成時にインスタンスタイプ(db.t3.mediumなど)を指定しますが、Aurora Serverlessではデータベースの負荷状況に応じた性能で稼働します。また、データベースの需要がないときはDBインスタンスを停止し、需要があれば自動的に起動します。データベースの利用率に変動のあるシステムや、利用量の予測が難しいシステムに使用すると、コスト削減の効果が期待できます。
ElastiCache
ElastiCacheはフルマネージド型のインメモリデータベースサービスです。
インメモリデータベースとは、データストレージにメモリを使用するデータベースのことです。SSDのようなディスクストレージよりも高速・安定したアクセスが可能で、主にパフォーマンスを重視するアプリケーションに利用されています。RDSやRedshiftなど他のデータベースサービスと連携し、クエリの結果をElastiCacheにキャッシュさせることで全体的なパフォーマンスを向上させる、というような使い方ができます。
本設問のポイントは以下の通りです。
・リードレプリカ(参照専用のデータベースとして動作する、データベースのレプリカ)が最大数(5台)に達している
→ これ以上リードレプリカによる参照リクエストの分散はできない
・パフォーマンスの改善施策が必要である
リードレプリカを増やすことなくパフォーマンスを改善するためには、ElastiCacheとの連携が有効です。ユーザーが高頻度でアクセスするデータをElastiCache上に保持しておくことでRDSへのリクエストを減少させ、リードレプリカの数も減らすことができます。
ElastiCacheのデータベースエンジン「Redis」は高パフォーマンス+高可用性に加えて機密性を提供します。Memcachedには機密性に関する設定はありません。
Redisには、データの暗号化や、SSL/TLSによる通信の暗号化、クライアントをパスワードで認証するRedis認証を行うことができます。これらを利用するには、ElastiCacheのデータベース作成時に「Redis」を選択し、暗号化を有効にする必要があります。

なお、セキュリティの各項目はデフォルトでは無効になっています。セキュリティの項目(データの暗号化・復号や認証など)はパフォーマンスに影響を与える可能性がありますので、利用する際は考慮が必要です。
Amazon ElastiCacheにはKVS(Key-Value Store:Key-Value型のデータストア)型のデータベースエンジン「Memcached」と「Redis」が用意されており、データベースを構築する際に選択することができます。
※Key-Value型 … 保存するデータ(Value)とそれを特定するためのキー(Key)がペアになった構成のデータセットのこと

Redshiftではデータベースのバックアップ(スナップショット)を異なるリージョンに作成することができます。
DynamoDBではバックアップの作成先のリージョンを指定することはできません。
RDSではリードレプリカという参照専用のレプリカを作成することにより、パフォーマンスを向上させることができます。DynamoDBが3つのAZに保存するテーブルは参照専用ではなく、パフォーマンス向上を目的とした仕組みではありませんので、リードレプリカとは別のものです。
Amazon DynamoDB Accelerator(DAX)は、DynamoDBのインメモリのキャッシュクラスタです。
DAXを利用することにより、ミリ秒(千分の一秒)だったレスポンスをマイクロ秒(百万分の一秒)レベルのパフォーマンスにまで向上させることができます。

キャッシュであるDAXからデータを取得することができれば、DynamoDBへアクセスする回数も削減されるため、RCUを抑えることもできます。
Redshift Spectrum
Redshift Spectrumとは、S3上のデータをRedshiftの外部テーブルとして参照できるようにした機能です。S3のデータをいったんRedshiftへ取り込んでからアクセスを行うよりも高速にアクセスできます。

S3上のデータ(外部テーブル)には複数のRedshiftクラスタからアクセスできたり、Redshift内のデータとS3上のデータに対してクエリを実行することもできます。また、利用頻度の低いデータをS3上に保持しておくことでRedshiftのディスクスペースを節約できるという利点もあります。
S3上のデータ(外部テーブル)には複数のRedshiftクラスタからアクセスできたり、Redshift内のデータとS3上のデータに対してクエリを実行することもできます。
RedshiftおよびRedshift SpectrumがS3上で扱うことのできるファイル形式には「構造化データ(RDBMSで利用されている形式。行・列の概念があるデータ)」と「半構造化データ(構造化されていないデータ形式のうちXMLなど規則性のあるもの)」があります。
Amazon DynamoDB
Amazon DynamoDBでは、テーブルに対する書き込み・読み込みのスループットを「キャパシティユニット」という単位で管理しています。
これは1秒間にどれだけ読み込み・書き込みを行うかを予約する設定で、容量が大きいほど料金がかかります。

また、DynamoDBのデータはパーティションという単位で分散して保存されます。パーティション分割によって一か所にデータを集中させないようにすることで、プロビジョニング(予約)されたスループットを保てるようにしています。従って、プロビジョニングされたキャパシティの量、すなわちキャパシティユニットを増やすとパーティションの数が多くなり、スループットが高くなります。
DynamoDBのS3へのエクスポート機能は、既存のテーブルデータを任意のS3バケットに直接エクスポートする機能です。ユーザはこの機能のために独自のアプリケーションを用意したり、追加のコードを記述したりする必要はありません。また、この機能を使用したデータのエクスポートでは、対象のテーブルに設定されたRCUを消費せず、テーブルの可用性やパフォーマンスにも影響を及ぼさないという点が大きなメリットです。
なお、この機能は、内部的にDynamoDBの継続的バックアップの機能(ポイントインタイムリカバリの前提となる機能)を使用しているため、対象のテーブルのポイントインタイムリカバリを有効にしておく必要があります。
Amazon DynamoDBのグローバルテーブルは、DynamoDBテーブルを複数のリージョンにまたがって運用できるサービスです。複数のリージョンにDynamoDBテーブルが自動的にレプリケートされ、ユーザーは地理的に近いリージョンのDynamoDBテーブルへ高速な読み込みと書き込みが可能になります。データのレプリケーションは通常1秒以内に完了し、リージョン間のデータ冗長化によって高可用性が確保されます。
グローバルテーブルでは、通常は1秒以内にグローバルテーブル内の他リージョンのDynamoDBテーブルすべてにレプリケートされます。また、複数リージョンでデータが冗長化されるので高可用性が確保されます。
Amazon DynamoDBでは、テーブルに対する書き込み・読み込みの量と利用料金が関係しています。
- オンデマンドモード … 書き込み・読み込みのリクエスト単位で利用料金がかかる
- プロビジョニングモード … 1秒間に行う書き込み・読み込みの量で利用料金が異なる
オンデマンドモードのオンデマンド(On Demand)とは「要求に応じて」を意味する熟語であり、ユーザーが要求して利用した分だけのサービスが提供されることをいいます。DynamoDBの場合も同様に、リクエストを発行した分だけ料金が請求されます。
以下はAWSが提供する主なデータベースサービスです。
DynamoDBはNoSQLのデータベースサービスで、Key-Value型という「保存するデータ(Value)」とそれを特定するための「キー(Key)」がペアになっている形式のデータを扱います。シンプルな構造であるためデータアクセスのパフォーマンスは非常に高く、ピーク時には秒間2000万件のリクエストに対応します。更にストレージの容量制限もありませんので拡張性にも優れています。
また、DynamoDBでは、テーブルに対する書き込み・読み込みの量と利用料金が関係しており、書き込み・読み込みは「キャパシティユニット」という単位で管理されています。これは1秒間にどれだけ読み込み・書き込みを行うかを予約する設定で、容量が大きいほど料金がかかりますが、高いパフォーマンスを発揮することができます。
設問のケースでは、データを永続的に保持することやその上限も不明であることから、ストレージの容量制限がないDynamoDBが適しています。また、アクセス頻度の低いデータであっても取り出しが1桁ミリ秒(千分の一秒)という高パフォーマンスを求められていますが、コスト面の制約がない、という条件からRCUを大きくすることで対応が可能です。
DynamoDBでは、Key-Value型という「保存するデータ(Value)」とそれを特定するための「キー(Key)」がペアになっている形式のデータを扱います。
また、DynamoDBでは、ドキュメント型という、階層的なデータ構造をもったJSON形式のデータの扱いについてもサポートしています。JSONは、階層的なデータ構造を簡単に表現することができるデータフォーマット(形式)です。DynamoDBにJSON形式のデータを格納することで、階層的なデータの効率的な管理が実現できます。

Amazon DynamoDBには2つのバックアップ方法があります。
「オンデマンドバックアップ」は、ユーザーが任意のタイミングで作成するバックアップのことです。マネジメントコンソールまたはAPIを利用して、テーブルの完全なバックアップを作成します。
自動的にバックアップを行いたい場合は「ポイントインタイムリカバリ(PITR)」を有効にします。オンデマンドバックアップとは違い、差分バックアップが定期的に自動で取得されます。リカバリ時は、35日前まで遡ることができます。なお、どちらのバックアップ処理もパフォーマンスへ影響を与えることはありません。
DynamoDBでは以下の2つの読み込みモードをサポートしています。
○結果整合性のある読み込み(デフォルト)
一時的には読み込んだデータが最新ではないタイミングが発生する可能性はあるが、最終的には読み出すデータは最新のものとなる(書き込みから少し時間をおくことで回避できる)。
○強力な整合性のある読み込み
必ず最新のデータを取り出すことができる。ただし読み込み時のコストが2倍になる、レイテンシが高くなる可能性がある、などの条件がつく。
大規模に利用する場合は「リザーブドキャパシティ」を用いることもできます。
リザーブドキャパシティはWCU、RCUともに100ユニット単位で予約購入する制度で、通常のプロビジョニングモードよりも割安に利用できます。

リザーブドキャパシティは読み込み・書き込みにわけて購入できます。また、購入したキャパシティユニットは各テーブルに割り振ることができます。
例えば、50のRCUを設定しているテーブルが二つある場合、読み込みキャパシティユニットを100購入することで2つのテーブルに割り当てることができます。
JSON形式のデータも格納することができます。
Amazon Redshift
Amazon Redshiftは、AWSが提供するデータベースサービスの一つです。

データウェアハウス(DWH:Data WareHouse)とは、複数のシステムからデータを収集・統合・蓄積し、分析に使用するデータベースです。蓄積したデータは、例えば時系列や顧客のデータに基づいて分析され、結果はシステム効率化や経営改善などの意思決定に利用されます。
DWHでは、基本的にデータの削除・更新は行わずに追加(蓄積)されていきますので通常のデータベースよりも多くの容量が必要になります。RedshiftではPB(ペタバイト、TB:テラバイトの上の単位)級のストレージに対応しており、大量のデータを扱うことができます。
Redshiftのアーキテクチャは以下のようになっています
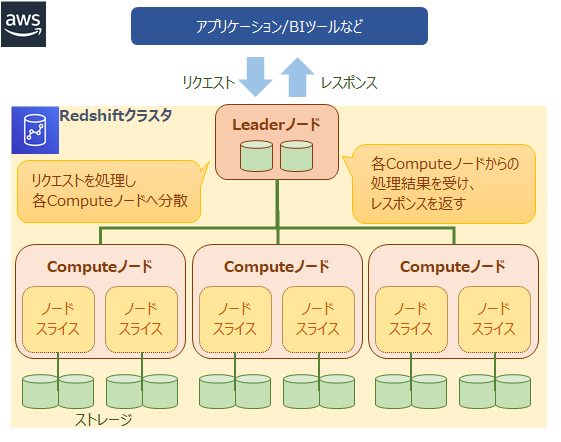
・Leaderノード(リーダーノード)
各クラスタに一台だけ存在する司令塔(Leader)となるノードです。
アプリケーションなどからのリクエストを受け付けて各Computeノードへ割り振り、またその結果を取りまとめてアプリケーションへ返す役割を果たします。
・Computeノード(コンピュートノード)
Leaderノードからの命令を処理するノードです。
一つのComputeノードはCPU、メモリ、ストレージを搭載しており、Computeノードを増やすことでパフォーマンスを向上させることができます。
Amazon Redshiftでは、スナップショットを採取することでバックアップをとります。スナップショットは、RedshiftのディスクイメージをAmazon S3(※)へ保存します。
※Amazon S3(Simple Storage Service)… AWSのストレージサービス。詳細は分野「S3」を参照
スナップショットは異なるリージョンへ保存することもできます。これを「クロスリージョンスナップショット」と呼びます。
異なるリージョンへとったスナップショットからRedshiftクラスタを再構築できるので、大規模な災害への対策(Disaster Recovery:ディザスタリカバリ)や異なるリージョンでRedshiftクラスタを構築する場合に有効です。
ElastiCache
ElastiCacheはフルマネージド型のインメモリデータベースサービスです。
インメモリデータベースとは、データストレージにメモリを使用するデータベースのことです。SSDのようなディスクストレージよりも高速・安定したアクセスが可能で、主にパフォーマンスを重視するアプリケーションに利用されています。
ElastiCacheにはKVS(Key-Value Store:Key-Value型のデータストア)型のデータベースエンジン「Redis」「Memcached」が用意されています。
また、ElastiCacheはフルマネージド型のサービスですので、データベースのセットアップや利用状況の監視、ソフトウェアへのパッチ適用などはAWSによって管理されています。
DynamoDB Streams
Amazon DynamoDBのDynamoDB Streams(ストリーム)とは、テーブルに対して行われた直近の24時間の変更(追加や更新、削除)をログに保存する機能です。ストリームを参照することによって、いつ誰がどのようにテーブルを更新したかがわかります。
ログには、アプリケーションがリアルタイムにアクセスできるため、変更内容に応じて処理を組み込むことができます。例えば、ログを監視し問題のある処理があった場合はアラートを上げさせたり、プロフィール画像を更新(追加)したらフレンドに通知させるというような運用が可能です。
Aurora
Auroraにおいて、データベースインスタンスへの接続は「エンドポイント(接続先)」によって制御されます。
エンドポイントには以下のようなものがあります。

クラスターエンドポイントは更新も参照も行うことができますが、参照クエリが多いと更新処理を圧迫してしまいます。用途ごとにエンドポイントを使い分けることで負荷を分散し、全体的なパフォーマンス改善を図ることができます。
設問では、レプリカインスタンスを作成し読み取りを行うクエリをレプリカインスタンスへ向けて行う、という題意から、クラスターエンドポイントから読み取りエンドポイントへ接続を切り替えることで負荷を軽減させる、ということが読み取れます。
Amazon Aurora Global Database(Auroraグローバルデータベース)は、Auroraデータベースを複数のリージョンにまたがって運用できるサービスです。例えば、東京リージョンで稼働しているデータベースを大阪リージョンにも配置できるということです。Auroraグローバルデータベースを使用しても、ユーザーは二つのリージョンのデータベースを管理する必要はありません。データはプライマリとして稼働しているメインのリージョンからセカンダリリージョンへレプリケートされます。
グローバルデータベースの大きな利点は以下の2点です。
1. データベースアクセスを世界中から高速に行える(レイテンシの向上)
2. リージョン単位で発生した大規模な障害の災害対策(ディザスタリカバリ:DR)になる
異なるリージョンからデータを読み取りたい場合はリードレプリカを異なるリージョンに配置することもできますが、Auroraグローバルデータベースは書き込みも異なるリージョンから行えます。
また、Auroraグローバルデータベースは災害復旧時に非常に高い効果を発揮します。プライマリリージョンのデータベースが停止した場合、セカンダリリージョンのデータベースを昇格(フェイルオーバー)させ運用を継続できます。Auroraグローバルデータベースでは、一般的にディザスタリカバリの指標として使用されるRPO(目標復旧時点)を 1秒、RTO(目標復旧時間)を1分未満と定めています。
※RPO(Recovery Point Objective:目標復旧時点) … どの時点までのデータを復旧させるか。データベースの更新頻度が高い場合は、0秒(停止直前)のデータ復旧が求められる。
※RTO(Recovery Time Objective:目標復旧時間) … どのくらいの時間で(いつまでに)復旧させるか。サービスやシステムを停止していられる時間。
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント