
AWS Glueは、フルマネージドのサーバーレスETLサービスです。
Glue(糊)の名の示す通り、複数のデータソース(S3やDynamoDBなど)からデータを抽出し、変換・統合したデータをターゲット(Redshiftなど)へ格納するといった、データ分析における橋渡しの役割を担います。
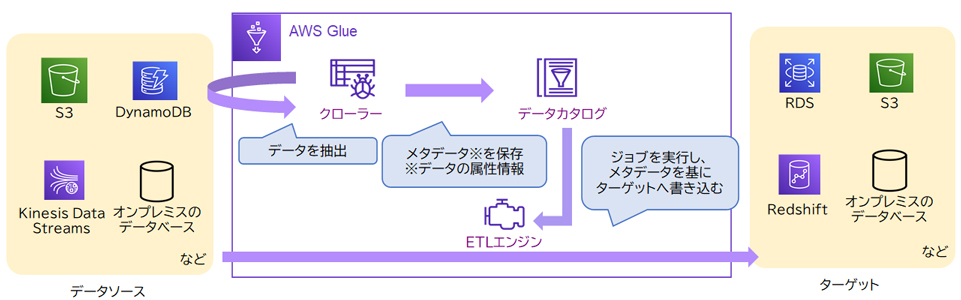
「クローラー」は、データソースからデータを抽出し、「データカタログ」を作成します。
データカタログとは、抽出したデータのメタデータ(データの属性情報)が保存されたものです。データそのものではなく、データソースのどのデータをどのような方法で抽出するかなどの情報が保存されています。
作成したデータカタログを基に、ETLエンジンがデータソースからデータを抽出し、ターゲットへ書き出す処理を行います。このデータの変換およびターゲットへ書き出す処理を「ジョブ」と呼びます。変換処理は、既存のETLツールであるApache SparkやScalaを用いて自動生成したり、生成されたスクリプトを自分で編集することができます。
なお、Glueで作成したデータカタログは、Amazon EMR※やAmazon Athena※などの分析・クエリ実行サービスなどからも参照できます。Glueのクローラーで抽出したデータに対してAthenaでSQLクエリを実行する、といった利用もできます。
※Amazon EMR … ビッグデータの処理や分析を行うサービス。
※Amazon Athena … S3内のデータに対して直接SQLクエリを実行できるサービス。
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント