
# formatメソッドの引数の順序の指定
a, b, c = 1, 2, 3
print('a = {}, b = {}, c = {}'.format(a, b, c))
print('b = {1}, c = {2}, a = {0}'.format(a, b, c))
print('b = {kb}, c = {kc}, a = {ka}'.format(ka=a, kb=b, kc=c))
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
a = 1, b = 2, c = 3
b = 2, c = 3, a = 1
b = 2, c = 3, a = 1
# formatメソッドの余白と揃えの指定
print('{:<12}'.format(77)) # 左寄せ
print('{:>12}'.format(77)) # 右寄せ
print('{:^12}'.format(77)) # 中央揃え
print('{:=12}'.format(-77)) # 符号 余白文字 数値
print('{:*<12}'.format(77)) # これ以降、余白文字は'*'
print('{:*>12}'.format(77))
print('{:*^12}'.format(77))
print('{:*=12}'.format(-77))
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py

# formatメソッドの符号の指定
print('{:+} {:-} {: }'.format(77, 77, 77))
print('{:+} {:-} {: }'.format(-77, -77, -77))
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
+77 77 77
-77 -77 -77
# formatメソッドによる各種の指定
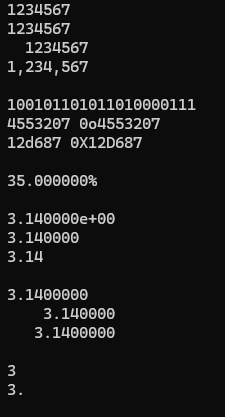
print('{:5d}'.format(1234567))
print('{:7d}'.format(1234567))
print('{:9d}'.format(1234567))
print('{:,}'.format(1234567))
print()
print('{:b}'.format(1234567))
print('{0:o} {0:#o}'.format(1234567))
print('{0:x} {0:#X}'.format(1234567))
print()
print('{:%}'.format(35 / 100))
print()
print('{:e}'.format(3.14))
print('{:f}'.format(3.14))
print('{:g}'.format(3.14))
print()
print('{:.7f}'.format(3.14))
print('{:12f}'.format(3.14))
print('{:12.7f}'.format(3.14))
print()
print('{:.0f}'.format(3.0))
print('{:#.0f}'.format(3.0))C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
# f文字列による書式化の例
a, b, c = 1, 2, 3
print(f'a = {a}, b = {b}, c = {c}')
print(f'{a} + {b} + {c} = {a + b + c}')C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
a = 1, b = 2, c = 3
1 + 2 + 3 = 6
# f文字列による書式化の例(その2)
a, b, c = 1, 2, 3
print(f'{a = }, {b = }, {c = }')
print(f'{a + b + c = }')
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
a = 1, b = 2, c = 3
a + b + c = 6
# 文字列s1とs2の同一性を判定
import sys
s1 = sys.intern(input('文字列s1:'))
s2 = sys.intern(input('文字列s2:'))
print(f's1 is s2 = {s1 is s2}')
print(f's1 is not s2 = {s1 is not s2}')C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
文字列s1:テスト
文字列s2:試験
s1 is s2 = False
s1 is not s2 = True
# 文字列内の全文字を順に表示(その1)
s = 'ABCDEFG'
print(f's[0] = {s[0]}')
print(f's[1] = {s[1]}')
print(f's[2] = {s[2]}')
print(f's[3] = {s[3]}')
print(f's[4] = {s[4]}')
print(f's[5] = {s[5]}')
print(f's[6] = {s[6]}')C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
s[0] = A
s[1] = B
s[2] = C
s[3] = D
s[4] = E
s[5] = F
s[6] = G
# 文字列内の全文字を順に表示(その1[改])
s = 'ABCDEFG'
print(f's[0] = {s[0]}')
print(f's[1] = {s[1]}')
print(f's[2] = {s[2]}')
print(f's[3] = {s[3]}')
print(f's[4] = {s[4]}')
print(f's[5] = {s[5]}')
print(f's[6] = {s[6]}')
print(f's[6] = {s[7]}') # エラーC:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
s[0] = A
s[1] = B
s[2] = C
s[3] = D
s[4] = E
s[5] = F
s[6] = G
Traceback (most recent call last):
File “C:\xxx.py”, line 12, in
print(f’s[6] = {s[7]}’) # エラー
~^^^
IndexError: string index out of range
# 文字列内の全文字を順に表示(その2)
s = 'ABCDEFG'
print(f's[-7] = {s[-7]}')
print(f's[-6] = {s[-6]}')
print(f's[-5] = {s[-5]}')
print(f's[-4] = {s[-4]}')
print(f's[-3] = {s[-3]}')
print(f's[-2] = {s[-2]}')
print(f's[-1] = {s[-1]}')
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
s[-7] = A
s[-6] = B
s[-5] = C
s[-4] = D
s[-3] = E
s[-2] = F
s[-1] = G
# 文字列内の全文字を順に表示(その2[改])
s = 'ABCDEFG'
print(f's[-7] = {s[-7]}')
print(f's[-6] = {s[-6]}')
print(f's[-5] = {s[-5]}')
print(f's[-4] = {s[-4]}')
print(f's[-3] = {s[-3]}')
print(f's[-2] = {s[-2]}')
print(f's[-1] = {s[-1]}')
print(f's[-8] = {s[-8]}') # エラー
C:\Users\keieikikaku-02\Downloads\NewMeikaiPython_2nd\chap06>python xxx.py
s[-7] = A
s[-6] = B
s[-5] = C
s[-4] = D
s[-3] = E
s[-2] = F
s[-1] = G
Traceback (most recent call last):
File “C:\xxx.py”, line 12, in
print(f’s[-8] = {s[-8]}’) # エラー
~^^^^
IndexError: string index out of range
# 読み込んだ文字列内の全文字をfor文で走査して表示
s = input('文字列:')
for i in range(len(s)):
print(f's[{i}] = {s[i]}')
C:>python xxx.py
文字列:テスト
s[0] = テ
s[1] = ス
s[2] = ト
# 読み込んだ文字列内から文字を探索
s = input('文 字 列s:')
c = input('探す文字c:')
print(f'文字{c}は', end='')
for i in range(len(s)):
if s[i] == c:
print(f's[{i}]に入っています。')
break
else:
print('入っていません。')
C:>python xxx.py
文 字 列s:テスト
探す文字c:ス
文字スはs[1]に入っています。
# 文字列s1とs2の大小関係および等価性を判定
s1 = input('文字列s1:')
s2 = input('文字列s2:')
print(f's1 < s2 = {s1 < s2}')
print(f's1 <= s2 = {s1 <= s2}')
print(f's1 > s2 = {s1 > s2}')
print(f's1 >= s2 = {s1 >= s2}')
print(f's1 == s2 = {s1 == s2}')
print(f's1 != s2 = {s1 != s2}')
C:>python xxx.py
文字列s1:テストメール
文字列s2:メール
s1 < s2 = True
s1 <= s2 = True
s1 > s2 = False
s1 >= s2 = False
s1 == s2 = False
s1 != s2 = True
# 文字列s1とs2の同一性を判定
s1 = input('文字列s1:')
s2 = input('文字列s2:')
print(f's1 is s2 = {s1 is s2}')
print(f's1 is not s2 = {s1 is not s2}')
C:>python xxx.py
文字列s1:1qaz2wsx
文字列s2:qa
s1 is s2 = False
s1 is not s2 = True
# 文字列txt内に文字列ptnは含まれているか
txt = input('文字列txt:')
ptn = input('文字列ptn:')
if ptn in txt:
print('ptnはtxtに含まれています。')
else:
print('ptnはtxtに含まれていません。')
C:>python xxx.py
文字列txt:1qaz2wsx
文字列ptn:1qaz
ptnはtxtに含まれています。
# 文字列txt内に文字列ptnは含まれているか(別解:not in演算子)
txt = input('文字列txt:')
ptn = input('文字列ptn:')
if ptn not in txt:
print('ptnはtxtに含まれていません。')
else:
print('ptnはtxtに含まれています。')
C:>python xxx.py
文字列txt:1qaz2wsx
文字列ptn:2wsx
ptnはtxtに含まれています。
# 文字列内の全文字をenumerate関数で走査して表示
s = input('文字列:')
for i, ch in enumerate(s):
print(f's[{i}] = {ch}')
C:>python xxx.py
文字列:1qaz2wsx
s[0] = 1
s[1] = q
s[2] = a
s[3] = z
s[4] = 2
s[5] = w
s[6] = s
s[7] = x
# 文字列内の全文字をenumerate関数で走査(1からカウント)
s = input('文字列:')
for i, ch in enumerate(s, 1):
print(f'{i}番目の文字:{ch}')
C:>python xxx.py
文字列:1qaz2wsx
1番目の文字:1
2番目の文字:q
3番目の文字:a
4番目の文字:z
5番目の文字:2
6番目の文字:w
7番目の文字:s
8番目の文字:x
# 文字列内の全文字をenumerate関数で逆順に走査して表示
s = input('文字列:')
for i, ch in enumerate(reversed(s), 1):
print(f'後ろから{i}番目の文字:{ch}')
C:>python xxx.py
文字列:1qaz2wsx
後ろから1番目の文字:x
後ろから2番目の文字:s
後ろから3番目の文字:w
後ろから4番目の文字:2
後ろから5番目の文字:z
後ろから6番目の文字:a
後ろから7番目の文字:q
後ろから8番目の文字:1
# 文字列内の全文字を走査して表示
s = input('文字列:')
for ch in s:
print(ch, end='')
print()
C:>python xxx.py
文字列:1qaz2wsx
1qaz2wsx
# 文字列内の全文字を逆順に走査して表示
s = input('文字列:')
for ch in s[::-1]:
print(ch, end='')
print()
C:>python xxx.py
文字列:1qaz2wsx
xsw2zaq1
# 文字列内の全文字を逆順に走査して表示(reversed関数を利用)
s = input('文字列:')
for ch in reversed(s):
print(ch, end='')
print()
C:>python xxx.py
文字列:1qaz2wsx
xsw2zaq1
# 文字列に含まれる文字列を探索
txt = input('文字列txt:')
ptn = input('文字列ptn:')
try:
print(f'txt[{txt.index(ptn)}]にptnが含まれます。')
except ValueError:
print('ptnはtxtに含まれません。')
C:>python xxx.py
文字列txt:1qaz2wsx
文字列ptn:1qaz
txt[0]にptnが含まれます。
# 文字列に含まれる文字列を探索
txt = input('文字列txt:')
ptn = input('文字列ptn:')
if (c := txt.count(ptn)) == 0:
# 含まれない
print('ptnはtxtに含まれません。')
elif c == 1:
# 1個だけ含まれる
print(f'ptnがtxtに含まれるインデックス:{txt.find(ptn)}')
else:
# 2個以上含まれる
print(f'ptnがtxtに含まれる先頭インデックス:{txt.find(ptn)}')
print(f'ptnがtxtに含まれる末尾インデックス:{txt.rfind(ptn)}')
C:>python xxx.py
文字列txt:1qaz2wsx
文字列ptn:1qaz
ptnがtxtに含まれるインデックス:0
# 二つの文字列を一度に読み込む(コンマで区切る)
a, b = input('文字列a,b:').split(',')
print(f'a = {a}')
print(f'b = {b}')
C:>python xxx.py
文字列a,b:1qaz,2wsx
a = 1qaz
b = 2wsx
# 書式化演算子%を用いた書式化
a, b, n = 12, 35, 163
f1, f2 = 3.14, 1.23456789
s1, s2 = 'ABC', 'XYZ'
print('nの10進表記=%d。' % n)
print('nの8進表記=%o。' % n)
print('%dは8進で%oで16進で%x。' % (n, n, n))
print('nは%5dでf1は%9.5fでf2は%9.5fです。' % (n, f1, f2))
print('"%s"+"%s"は"%s"です。' % (s1, s2, s1 + s2))
print('%dと%dの和は%dです。' % (a, b, a + b))
print('%(no1)d+%(no2)dと%(no2)d+%(no1)dはいずれも%(sum)dです。' %
{'no1': a, 'no2': b, 'sum': a + b})
C:>python xxx.py
nの10進表記=163。
nの8進表記=243。
163は8進で243で16進でa3。
nは 163でf1は 3.14000でf2は 1.23457です。
“ABC”+”XYZ”は”ABCXYZ”です。
12と35の和は47です。
12+35と35+12はいずれも47です。
# 書式化演算子%を用いた書式化(値をキーボードから読み込む)
a = int(input('整数a:'))
b = int(input('整数b:'))
c = int(input('整数c:'))
n = int(input('整数n:'))
f1 = float(input('実数f1:'))
f2 = float(input('実数f2:'))
s1 = input('文字列s1:')
s2 = input('文字列s2:')
print('nの10進表記=%d。' % n)
print('nの8進表記=%o。' % n)
print('%dは8進で%oで16進で%x。' % (n, n, n))
print('nは%5dでf1は%9.5fでf2は%9.5fです。' % (n, f1, f2))
print('"%s"+"%s"は"%s"です。' % (s1, s2, s1 + s2))
print('%dと%dの和は%dです。' % (a, b, a + b))
print('%(no1)d+%(no2)dと%(no2)d+%(no1)dはいずれも%(sum)dです。' %
{'no1': a, 'no2': b, 'sum': a + b})
C:>python xxx.py
整数a:10
整数b:5
整数c:6
整数n:1
実数f1:5
実数f2:6
文字列s1:1
文字列s2:2
nの10進表記=1。
nの8進表記=1。
1は8進で1で16進で1。
nは 1でf1は 5.00000でf2は 6.00000です。
“1”+”2″は”12″です。
10と5の和は15です。
10+5と5+10はいずれも15です。
# f文字列による書式化(生成した文字列を表示)
a = int(input('整数a:'))
b = int(input('整数b:'))
c = int(input('整数c:'))
n = int(input('整数n:'))
f1 = float(input('実数f1:'))
f2 = float(input('実数f2:'))
s = input('文字列s:')
print()
print(f'a / b = {a / b}')
print(f'a % b = {a % b}')
print(f'a // b = {a // b}')
print(f'bはaの{a / b:%}') # 百分率
print()
print(f' a b c') # 正 負
print(f'[+]{a:+5}{b:+5}{c:+5}') # '+' '-'
print(f'[-]{a:-5}{b:-5}{c:-5}') # '-'
print(f'[ ]{a: 5}{b: 5}{c: 5}') # ' ' '-'
print()
print(f'{c:<12}') # 左寄せ
print(f'{c:>12}') # 右寄せ
print(f'{c:^12}') # 中央揃え
print(f'{c:=12}') # 符号の後ろに余白文字
print()
print(f'n = {n:4}') # 少なくとも4桁
print(f'n = {n:6}') # 少なくとも6桁
print(f'n = {n:8}') # 少なくとも8桁
print(f'n = {n:,}') # 3桁ごとに,
print()
print(f'n = ({n:b})2') # 2進数
print(f'n = ({n:o})8') # 8進数
print(f'n = ({n})10') # 10進数
print(f'n = ({n:x})16') # 16進数(小文字)
print(f'n = ({n:X})16') # 16進数(大文字)
print()
print(f'f1 = {f1:e}') # 指数形式
print(f'f1 = {f1:f}') # 固定小数点形式
print(f'f1 = {f1:g}') # 形式を自動判別
print()
print(f'f1 = {f1:.7f}') # 精度は7
print(f'f1 = {f1:12f}') # 全体で12
print(f'f1 = {f1:12.7f}') # 全体で12+精度は7
print()
print(f'f2 = {f2:.0f}') # 小数部がなければ省略
print(f'f2 = {f2:#.0f}') # 小数部がなくても小数点
print()
print(f'{s:*<12}') # 左寄せ
print(f'{s:*>12}') # 右寄せ
print(f'{s:*^12}') # 中央揃え
print()
for i in range(65, 91): # 65~90の文字
print(f'{i:c}', end='')
print()
C:>python xxx.py
整数a:11
整数b:6
整数c:8
整数n:4
実数f1:2
実数f2:1
文字列s:6
a / b = 1.8333333333333333
a % b = 5
a // b = 1
bはaの183.333333%
a b c[-] 11 6 8
[ ] 11 6 8
8
8
8
8
n = 4
n = 4
n = 4
n = 4
n = (100)2
n = (4)8
n = (4)10
n = (4)16
n = (4)16
f1 = 2.000000e+00
f1 = 2.000000
f1 = 2
f1 = 2.0000000
f1 = 2.000000
f1 = 2.0000000
f2 = 1
f2 = 1.
6***********
***********6
*****6******
ABCDEFGHIJKLMNOPQRSTUVWXYZ
# 読み込んだ文字はアルファベットの何番目か
from string import *
c = input('アルファベット:')
if (idx := ascii_lowercase.find(c)) != -1:
print(f'小文字の{idx + 1}番目です。')
else:
idx = ascii_uppercase.find(c)
if idx != -1:
print(f'大文字の{idx + 1}番目です。')
else:
print(f'アルファベットではありません。')
C:>python xxx.py
アルファベット:f
小文字の6番目です。
# f文字列による文字列の連結
s1 = input('文字列s1:')
s2 = input('文字列s2:')
no = int(input('整数値no:'))
print(f'{s1}{s2}') # 文字列s1 + 文字列s2
print(f'{s1}{no}{s2}') # 文字列s1 + 整数no + 文字列s2
C:>python xxx.py
文字列s1:pdf
文字列s2:abc
整数値no:1
pdfabc
pdf1abc
# 書式化演算子%を用いた書式化の例
print('%3d' % 12345)
print('%5d' % 12345)
print('%7d' % 12345)
print()
print('%d / %d = %d' % (5, 3, 5 / 3))
print('%d %% %d = %d' % (5, 3, 5 % 3))
print()
print('%d %o %x' % (12345, 12345, 12345))
print('%e %f %g' % (1.234, 1.234, 1.234))
C:>python xxx.py
12345
12345
12345
5 / 3 = 1
5 % 3 = 2
12345 30071 3039
1.234000e+00 1.234000 1.234
# スライス式の利用例
s = 'ABCDEFGHIJKLMNOPQRSTUVWZYZ'
print(f's[:] = {s[:]}')
print(f's[:7] = {s[:7]}')
print(f's[5:] = {s[5:]}')
print(f's[5:11] = {s[5:11]}')
print(f's[-5:] = {s[-5:]}')
print(f's[::3] = {s[::3]}')
print(f's[::-1] = {s[::-1]}')
C:>python xxx.py
s[:] = ABCDEFGHIJKLMNOPQRSTUVWZYZ
s[:7] = ABCDEFG
s[5:] = FGHIJKLMNOPQRSTUVWZYZ
s[5:11] = FGHIJK
s[-5:] = VWZYZ
s[::3] = ADGJMPSVY
s[::-1] = ZYZWVUTSRQPONMLKJIHGFEDCBA
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント