
活性化関数とは、あるニューロンから次のニューロンへと出力する際に、 入力値を別の数値に変換して出力する関数
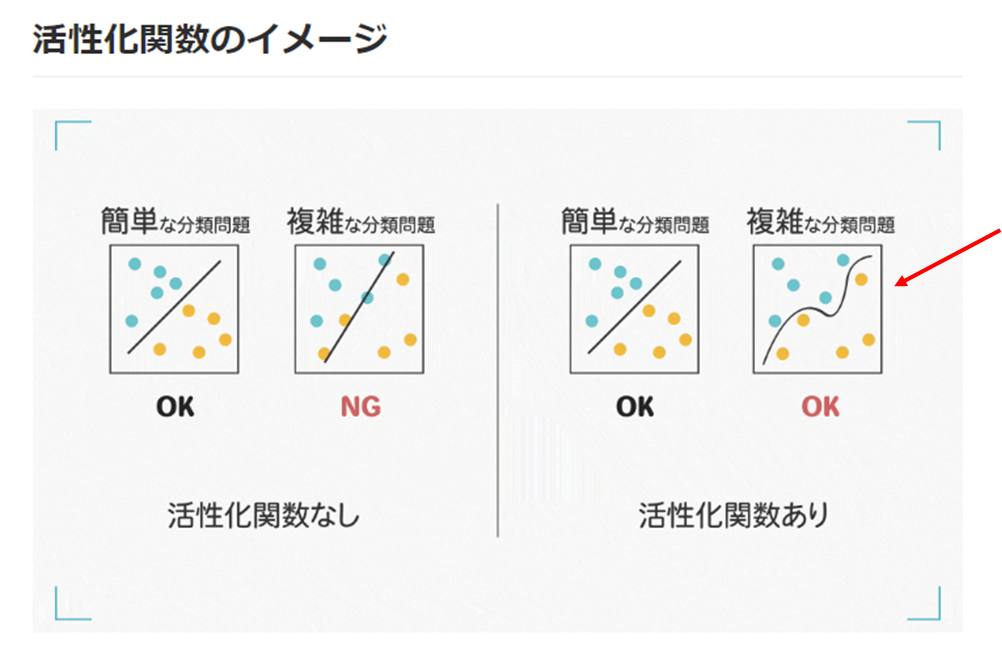
活性化関数なしではまっすぐな直線しか引くことができない、 しかし活性化関数を使うことでくねくねした曲線 を引くことができる →複雑な分類が可能になる
Contents
活性化関数の例
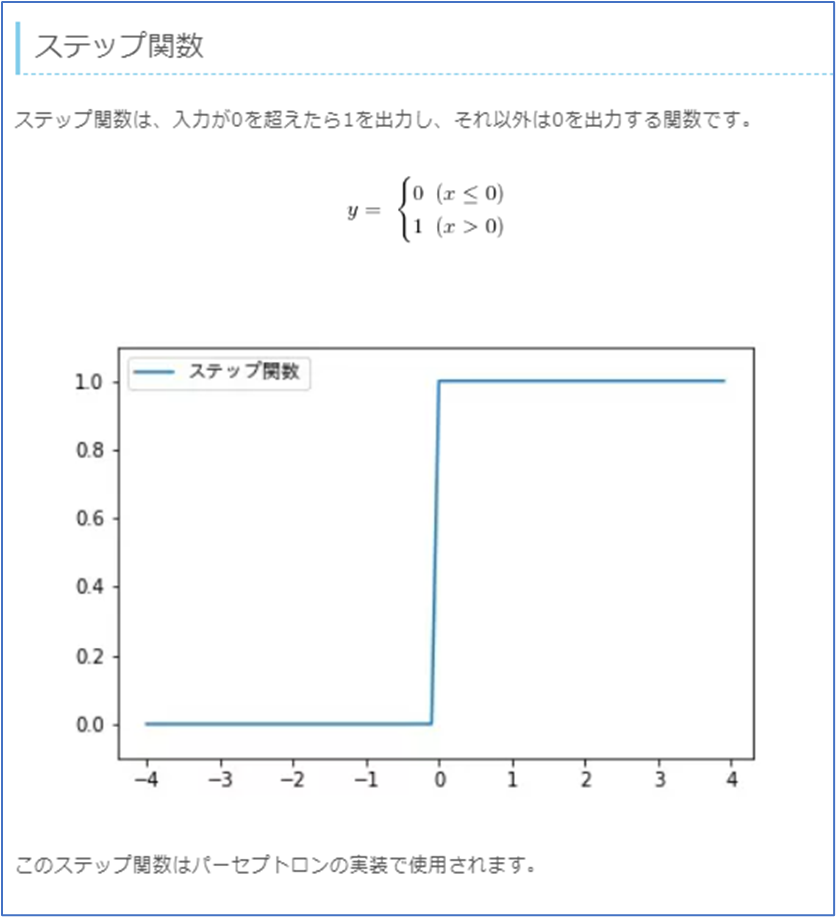
ステップ関数
入力が0を超えていれば入力をそのまま出力、0未満であれば0を出力する。実際にはあまり使用されない。
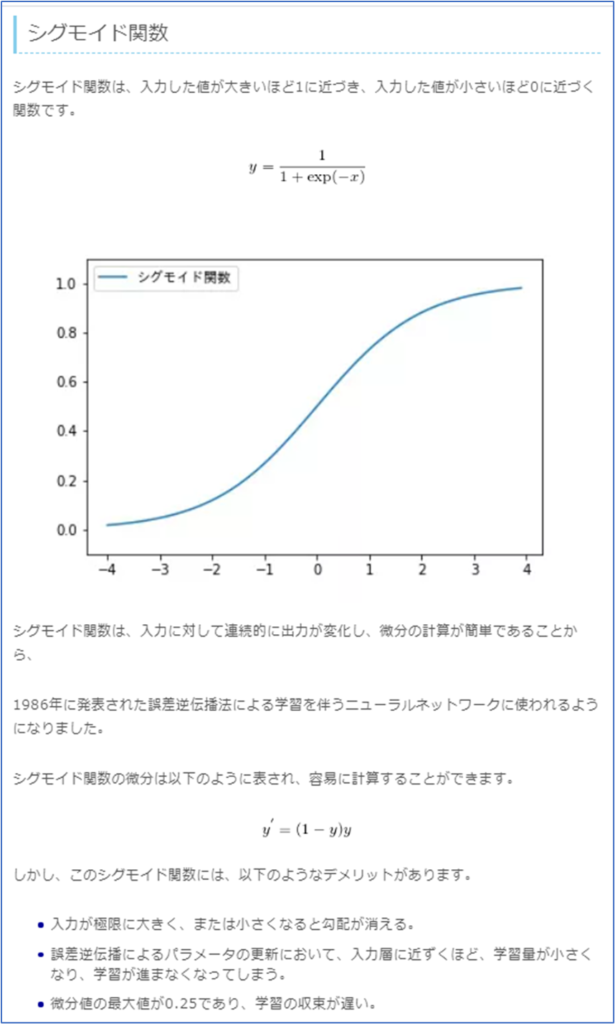
シグモイド関数
入力を0~1の間の値に変換する(正規化する)関数で、非線形。
実際にはあまり使用されない 微分すると0以下になってしまうことから、勾配消失問題が起きやすい。
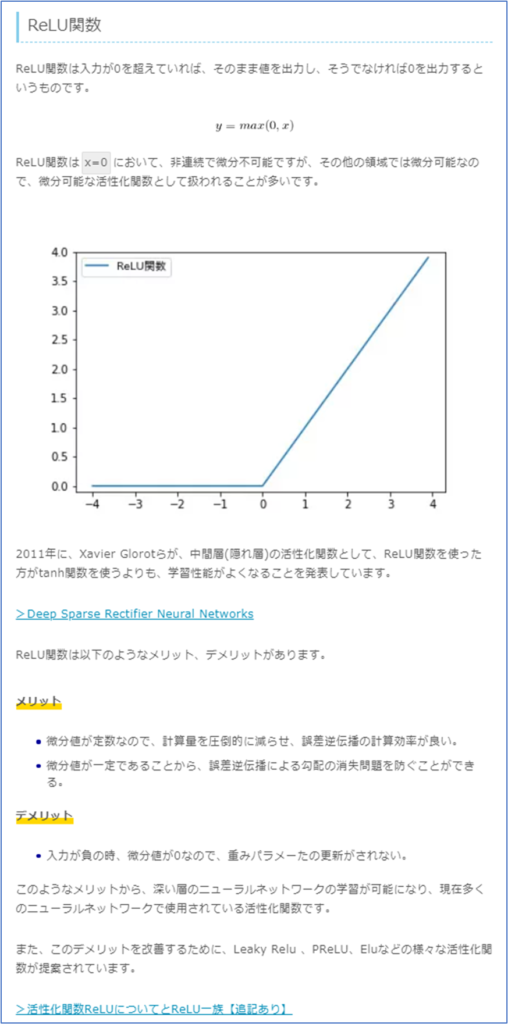
ReLU(レル)関数
主流の活性化関数 入力が0以下であれば出力は0。入力が0以上であれば入力値をそのまま出力する。
誤差逆伝播の際に勾配消失しにくい。
しかし,入力が0以下の場合の微分値が0になるため,学習がうまく行かない場合もある。
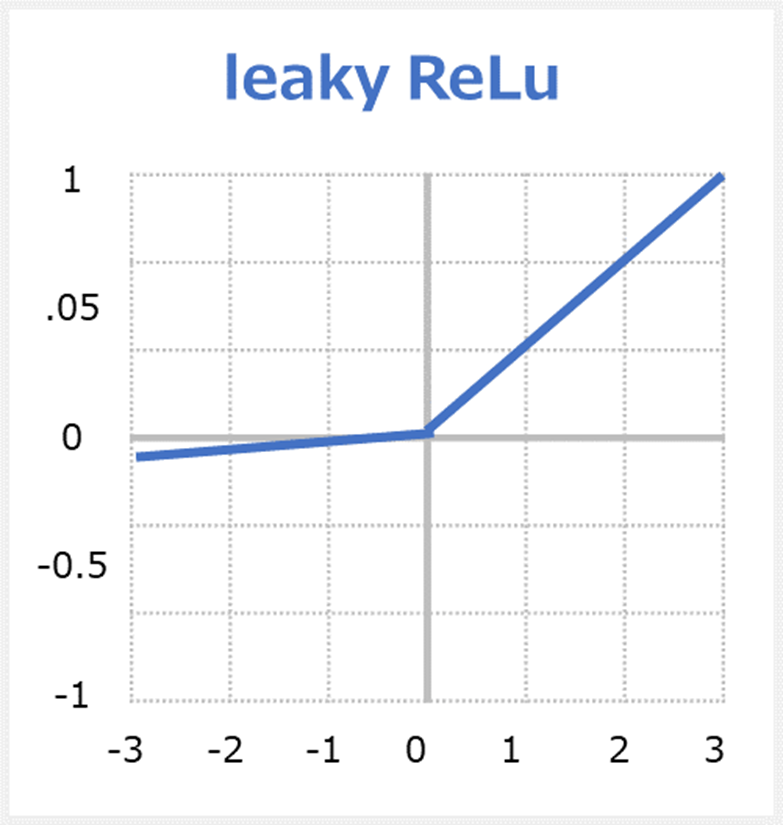
Leaky ReLU(リーキーレル)関数
ReLU関数は入力値が0以下の場合に、勾配が壊れやすいというデメリットがある。これに対応したものがこのLeaky ReLU関数。 ReLUの x < 0 側を傾けることで,手前の層に逆伝搬できるようにしたものである。 しかし、どちら優れているというわけではなく、ReLU関数とLeaky ReLU関数の両方を検証し、精度の高い方を採用することが多い。
Leaky ReLUの数式

tanh(ハイパボリックタンジェント)関数
-1から1の値を取る。
微分しても最大値が1となるためシグモイド関数より勾配消失問題が起きにくいです。

ソフトマックス関数
多値分類で使われる(服のサイズS・M・Lなど)。
出力層で使用される。出力の総和が1になるため確率として解釈する際に用いられる。

{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント