
大規模言語モデル(Large Language Models、LLM)とは、大量のテキストデータを使ってトレーニングされた言語モデルのこと。
言語モデルとは、より自然な文章の並びに対して高い確率を割り当て、文章として成立しない並びには低い確率を割り当てるものです。
代表例:GPT-3(OpenAI 2018年)、BERT(Google 2018年)、PaLM(Google 2022年)、LLaMA(Meta 2023年) LLMを活用した代表的なサービスとして、ChatGPT、BingのAIチャット、GoogleのBardが挙げられます。
≪LLMででてくる用語≫
Transformer
TransformerはRNN(再帰型ニューラルネットワーク)を使わずに、単語間のどこに注目すると良いか学習するAttention機構を使った仕組み これを使えばRNNよりも良い感じに言語を扱える 尚、上で例として挙げた、GPT3やBERT、PaLMはTransformerを使った言語モデル。
Attention機構
入力されたデータのどこに注目すべきかを特定する仕組み。
画像認識や時系列データにも応用されています。
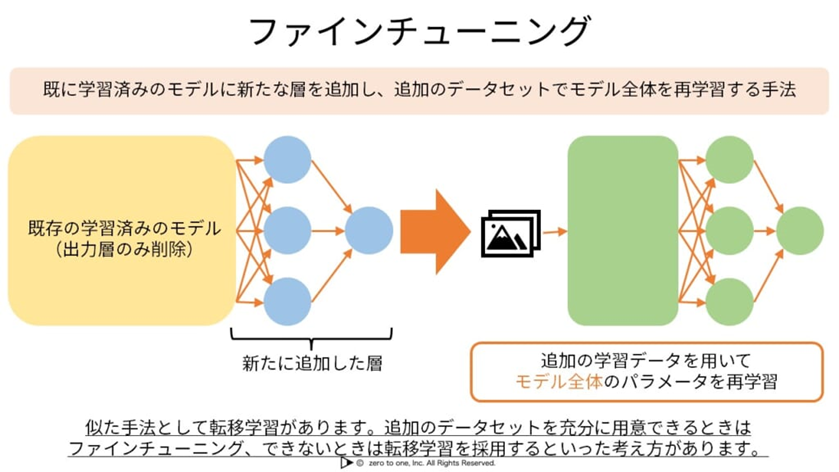
ファインチューニング
ファインチューニングとは、すでに学習済みのモデルに新たな層を追加し、モデル全体を再学習する手法。
1から学習するよりも短時間でデータモデルの構築が可能になります。
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント