
Amazon RDSのマルチAZ DBクラスターは、マルチAZ構成の新しい高可用性オプションです。従来のマルチAZ構成とは異なり、3つのアベイラビリティゾーンにまたがって配置されるため、可用性がさらに強化されています。また、従来のマルチAZ構成ではスタンバイインスタンスにアクセスできませんが、マルチAZ DBクラスターでは2つのスタンバイインスタンスがリードレプリカとしても機能し、読み取りアクセスが可能です。プライマリーインスタンスへの書き込みは、残り2台のリードレプリカに準同期レプリケーションされます。さらに、フェイルオーバー時には通常35秒未満で切り替わるため、アプリケーションのダウンタイムを最小限に抑えることができます。マルチAZ構成されたRDSは高可用性に優れていますが、リードレプリカが設置されておらず、読み取りパフォーマンスに限界があります。
[マルチAZ DBクラスターのイメージ図]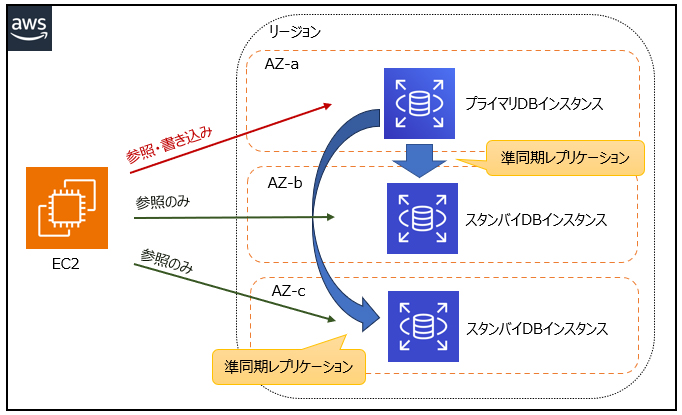
・マルチAZ構成されたRDS for MySQLデータベースを作成する
→マルチAZ構成されたRDSは高可用性に優れていますが、リードレプリカが設置されておらず、読み取りパフォーマンスに限界があります。
・EC2インスタンスにMySQLをセットアップする。EBSのスナップショットを使用してバックアップとリストアを自動化し、データの整合性を保つ
→EBSのスナップショットはバックアップには適していますが、フェイルオーバーや高可用性に対応していません。
・Aurora MySQLをシングルAZ構成でデプロイし、Auroraのリードレプリカを使用して読み取りパフォーマンスを向上させる
→AuroraはMySQL互換で高可用性と読み取りパフォーマンスの向上を提供しますが、シングルAZ構成では高可用性やフェイルオーバーを実現できません。
Contents
- 1 AWS X-Ray
- 2 ヘルスチェック
- 3 AWS Elastic Beanstalk
- 4 AWS Transfer Family
- 5 AWS Outposts
- 6 Amazon SQS
- 7 Auto Scaling
- 8 Amazon MQ
- 9 セッション情報の保存
- 10 Amazon SQS 可視性タイムアウト
- 11 Amazon Aurora Global Database
- 12 Amazon SQS
- 13 Amazon EBS
- 14 AWSが提供する代表的なデータベースサービス
- 15 AWS Site-to-Site
- 16 デッドレターキュー
- 17 NATゲートウェイ
- 18 SNS FIFO
- 19 Kinesis Data Streams
- 20 Amazon ECS
- 21 Amazon SQS
- 22 DynamoDBのS3へのエクスポート機能
- 23 Global Accelerator
- 24 Amazon EFS
- 25 ALB
- 26 Amazon API Gateway
- 27 災害復旧を考慮したマルチリージョンの利用
- 28 NLB
- 29 ALB(Application Load Balancer)
- 30 EBS
- 31 バックアップ
- 32 API Gateway Canaryリリース
- 33 Amazon SQS
- 34 Amazon Route 53
- 35 ALBのヘルスチェック
- 36 Amazon SQS
- 37 Amazon Route 53
- 38 EKS
- 39 Amazon EFS
- 40 AWS Storage Gateway
- 41 DynamoDB Streams
- 42 フェイルオーバー
- 43 Amazon EKS
- 44 Amazon Simple Notification Service(SNS)
- 45 AWS Step Functions
- 46 REST APIを用いてデータを受け付けるサービス
- 47 ストリーミングデータを変換処理へ配信するサービス
- 48 データ変換処理を実施するサービス
- 49 AWS Direct Connect
- 50 RDS
- 51 AWS Backup
- 52 Auto Scaling
- 53 NLB
- 54 Amazon ECS
AWS X-Ray
AWS X-Rayは、アプリケーションの動作に関するデータを収集・分析できるサービスです。主にトラブルシューティング目的で利用され、アプリケーション内のリクエストをトレースし、処理時間やレスポンスを分析することで、パフォーマンスのボトルネックやエラーの発生箇所を特定できます。
[リクエストのトレース例]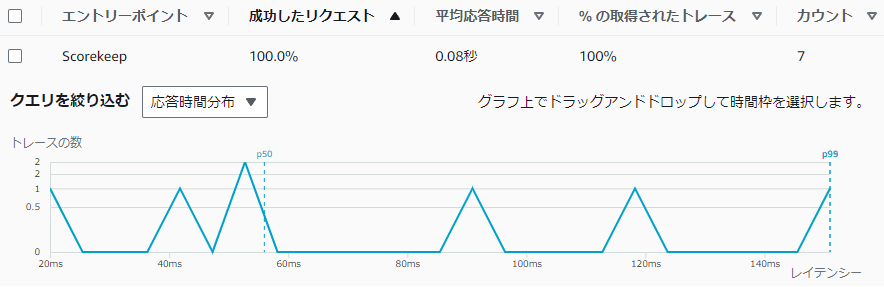
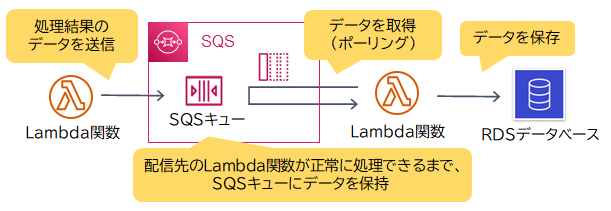
Amazon Simple Queue Service(SQS)はフルマネージドのメッセージキューイングサービスであり、サービス同士の橋渡しを担います。SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。
SQSでは、キュー内のメッセージは自動的に削除されず、受信側がメッセージを正常に処理した後にSQSキューから削除します。受信側の処理中にエラーが発生した場合は削除が実行されず、メッセージはSQSキューに残ります。
本設問のように、何らかの理由で受信側の処理が失敗した場合でも、問題が解決された後にSQSキューに残ったメッセージを再処理することで、データの損失を防ぐことができます。
ヘルスチェック
ALBとAuto Scalingグループを組み合わせると、ALBのターゲットグループ配下のEC2インスタンスに障害が発生した時や負荷が増大した時に、Auto Scalingが自動的に新規のインスタンスを立ち上げてALBのターゲットグループに追加します。
複数のEC2インスタンスをALB配下のAuto Scalingグループに配置することで、可用性が向上します。
リソースがEC2インスタンスの場合、Auto Scalingのヘルスチェックのタイプには「EC2」と「ELB」があります。「EC2」はインスタンスのステータスチェックの結果を確認し、「ELB」は指定した接続先への応答確認をします。Auto Scalingのヘルスチェックで異常となったリソースは、自動的に終了されます。
デフォルトでは「EC2」が有効、「ELB」は無効になっていますが、「EC2」「ELB」ともに有効にすることが推奨されています。
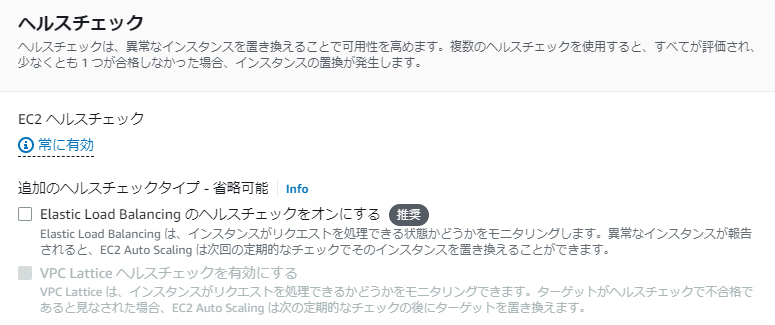
Auto Scalingグループのヘルスチェックの設定で「EC2」が有効、「ELB」が無効になっている場合、ELBからのヘルスチェックに応答がないインスタンスは負荷分散先からは除外されますが、EC2のステータスチェック(ハードウェアやネットワーク)が正常であればインスタンスは起動した状態が続きます。例えば、ELBヘルスチェックで指定したURLに異常(HTTP404エラーなど)が発生しても、インスタンス自体は正常に動作している場合、ALBから負荷分散されなくなりますが、インスタンスは終了しません。インスタンスが終了しないと新規インスタンスも起動しないので、サービスを継続できなくなる恐れがあります。
ヘルスチェックの設定で「ELB」も有効にすることで、ELBからのヘルスチェックに応答がないインスタンスが終了し、新たに正常なインスタンスが起動します。
設問の場合では、ALBのヘルスチェックで指定したURLに対して応答確認されるように設定し、Auto Scalingグループのヘルスチェックの設定でELBのヘルスチェックを有効にすることで、HTTPエラーが発生しても正常にサービスを継続できるようになります。
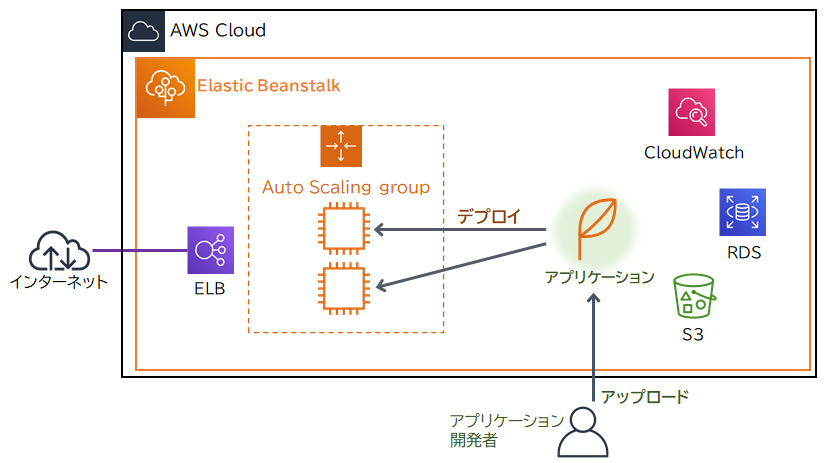
AWS Elastic Beanstalk
AWS Elastic Beanstalk は、アプリケーションが動作する環境を簡単に構築・管理できるサービスです。Elastic Beanstalkを使うことで、必要なインフラ(サーバー、データベース、ロードバランサーなど)を数クリックで自動的に設定し、アプリケーションをデプロイできます。高可用性の環境を手軽に構築することができ、環境が構築された後も運用管理はAWSによって行われるため、運用負荷を大幅に軽減できます。
また、Elastic Beanstalkは、Blue/Greenデプロイメント(環境を切り替えること)が容易に実行できます。Blue/Greenデプロイメントは、旧環境を稼働させながら新環境にバージョンアップしたアプリケーションをデプロイし、動作確認後に旧環境と新環境のURLをスワップする(切り替える)ことで実現できます。頻繁に機能をテストする必要があるケースに非常に適しており、ダウンタイムを最小限に抑えて新機能のリリースを行えます。
CloudFormationはインフラの自動作成に優れていますが、Elastic Beanstalkのように簡単に環境を切り替える機能がありません。また、各AWSサービスやロードバランサーなどのインフラストラクチャ(基盤)技術についての知識が必要で、運用負荷が高くなります。
AWS Elastic Beanstalkは、アプリケーションが動作する定番の構成を提供します。アプリケーションの開発者は、Elastic Beanstalkによって用意されている定番構成の中からアプリケーションの実行環境に適したものを選んで数クリックするだけで、環境(インフラ)を作成することができます。環境の作成後にアプリケーションをアップロードすることにより、デプロイ(実行環境への展開)を行うことができます。
AWS Transfer Family
AWS Transfer Familyは、AWSストレージ上へのセキュアなファイル転送を実現するマネージドサービスです。SFTP、FTPS、FTPなどをサポートし、Amazon S3やAmazon EFSへセキュアにファイルの転送が可能になります。Transfer Familyを利用することで、従来のようにFTPサーバーを自身で構築したり管理する必要がなくなり、運用上のオーバーヘッドを減らすことができます。
Transfer Familyの一つであるTransfer for SFTPと、ストレージサービスのEFSを使用することで、高可用性、耐障害性が確保されたSFTPサービスが構築できます。また、EC2インスタンスを使用してバッチ処理を行う際には、Auto Scalingを利用することで負荷に応じたスケーリングが可能となります。スケジュールされたスケーリングポリシーにより、バッチ処理に合わせてインスタンスをスケールアップし、処理が終了したらスケールダウンするように設定することもできます。
・オンプレミスのSFTPサーバーからDataSync経由で請求データファイルをS3バケットに転送する。スケジュールされたスケーリングポリシーを持つAuto Scalingグループに属するEC2インスタンスにオンプレミスのアプリケーションを移行し、S3バケットからファイルをダウンロードしてバッチ処理を実行する
→Transfer for SFTPで直接S3にデータを転送する方がシンプルです。DataSyncを使うことで余計なステップが増え、運用の複雑さが増します。また、オンプレミスのSFTPサーバーが維持されることで、オンプレミスのインフラに依存した障害リスクが残ります。
AWS Outposts
AWS Outpostsは、AWSのインフラストラクチャやサービスをオンプレミスに拡張して利用できるフルマネージドサービスです。Outpostsを使用すると、AWSのラックやサーバーをオンプレミス環境に導入し、AWSのサービス(例:EC2、S3、RDS、EMRなど)をローカルで使用することができます。AWSがハードウェアの運用管理を行うため、時間的コストや人件費を抑え、効率的に業務を進めることが可能です。また、物理的なラックやサーバーを設置するため、オンプレミスとAWSのインフラストラクチャが物理的に接続され、低レイテンシー接続が可能になります。金融取引やリアルタイムデータ処理など低遅延が要求されるアプリケーションや、規制や契約上データをオンプレミスから移動できない場合に適したサービスです。
Amazon EMR(旧Amazon Elastic MapReduce)は、ビッグデータの処理や分析を行うサービスです。HadoopやSpark、Prestoなどの既存のビッグデータフレームワークを用いており、データを複数のサーバーに分散配置して並列に処理することで、迅速かつ効率的なデータ処理を実現します。
Outpostsでは、EMRがサポートされており、オンプレミス環境でHadoopやSpark、Prestoなどをクラウドと同様に使用可能です。ユーザーはインフラ管理の手間を減らし、アプリケーションに集中できます。
Amazon SQS
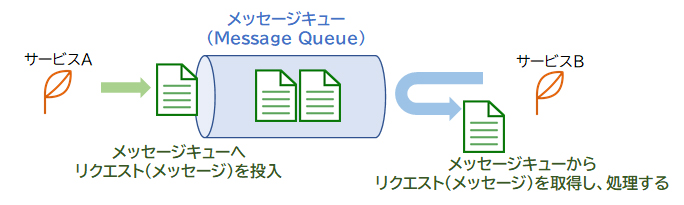
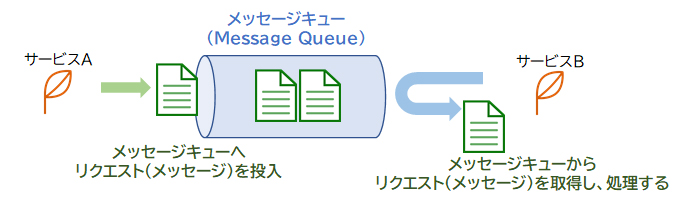
Amazon SQSはフルマネージドなメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。Amazon SQSはプル型であるため、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。

サービスAはクライアントからのリクエストを受け、キュー(queue)と呼ばれる領域にリクエスト(メッセージ)を投入します。サービスBはキューからメッセージを取得し、処理します。
Auto Scaling
Auto ScalingはAWSリソースを負荷状況や設定したスケジュールに従って自動的にスケーリングする機能です。リクエストが増加した場合、SQSとCloudWatch、Auto Scalingを連携することでインスタンスを自動的にスケーリングできます。リクエストの増加によりSQSキュー内にある処理待ちのメッセージ数(バックログ)がしきい値を超えたときにCloudWatchがアラートを上げ、Auto Scalingがインスタンスを増やします。
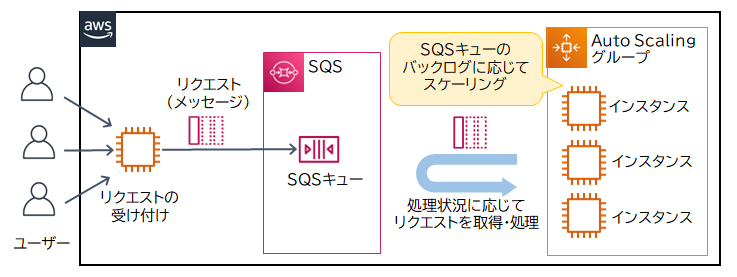
処理時間の異なる変換用アプリケーションと分析用アプリケーションの間にSQSを介すことで、各アプリケーションの処理状況がお互いに影響を与えにくくなります。また、SQSキューのバックログに基づいてEC2インスタンスをスケーリングすることでリクエストが増加しても対応できるようになり、データの損失が発生しにくくなります。
DynamoDBに保存するデータは3つのAZに自動的に保存されるので耐久性に優れており、セッション情報を永続的に保存できます。また、ElastiCacheのRedis型もマルチAZに対応しておりデータの永続保持が可能です。
Systems Manager Session Managerは、EC2インスタンスへブラウザ(マネジメントコンソール)やAWS CLIからセキュアにログインできる機能です。クライアントとサーバー間のセッション情報を管理する機能はありません。
Amazon MQ
Amazon MQは、Apache ActiveMQとRabbitMQに対応したフルマネージドのメッセージブローカーサービスです。メッセージブローカーサービスとは、複数のサービスやシステム間の連携に使用される「メッセージキュー※」を管理するサービスのことです。
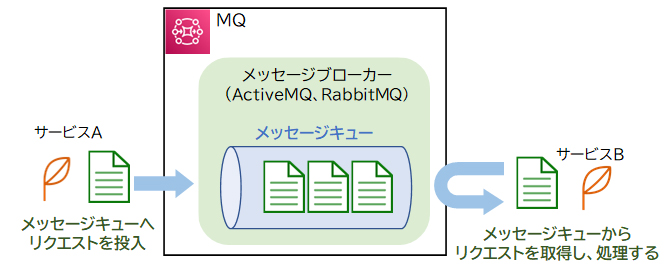
※メッセージキューについての詳細な説明は、分野「SQS」に記載されています。
Amazon MQは、Apache ActiveMQやRabbitMQといったオープンソースのメッセージブローカーと互換性があるので、既存環境から移行するアプリケーションに適しています。
セッション情報の保存
ンスタンスのスケーリングが発生するシステムでは、クライアントとのセッションを維持しているサーバーがスケールインした時に、セッション情報が破棄されてしまいます。セッションを安定して維持するためには、セッション情報をデータベースに保存してインスタンス間で共有するのが効果的です。セッション情報の保存には、NoSQLデータベースで高パフォーマンスな読み取り・書き込みが可能であるAmazon DynamoDBとAmazon ElastiCacheが適しています。
下記の図はDynamoDBを利用した例です。
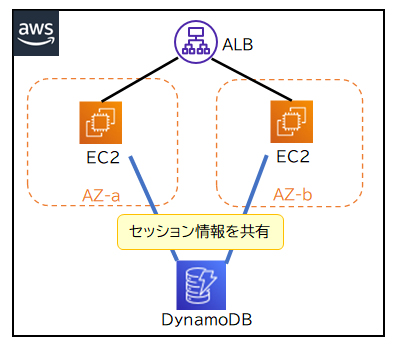
DynamoDBに保存するデータは3つのAZに自動的に保存されるので耐久性に優れており、セッション情報を永続的に保存できます。また、ElastiCacheのRedis型もマルチAZに対応しておりデータの永続保持が可能です。
Amazon SQS 可視性タイムアウト
Amazon SQSにおいて、キューのメッセージは受信側が明示的に削除の指示をしない限り削除されません。SQSのメッセージを受信するクライアントが複数ある場合、タイミングによっては、メッセージが削除される前に複数のクライアントでメッセージを受信してしまうことがあります。
可視性タイムアウトはこれを防ぐために、一度クライアントがメッセージを受信した後、指定時間(デフォルト30秒)が経過するまでそのメッセージが他のクライアントからは見えないようにします。
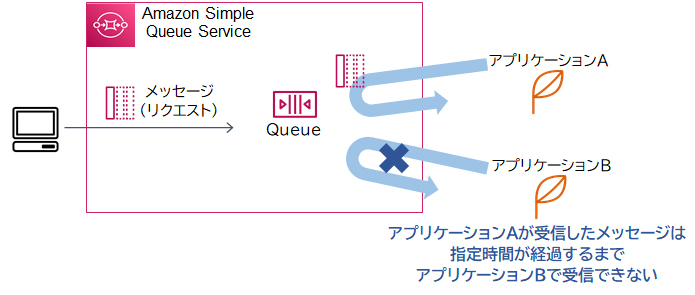
本設問の問題点は、同一のメッセージが重複して処理されることです。これは、メッセージを処理するのに時間がかかり、あるインスタンスが処理を完了する前に、別のインスタンスが同一のメッセージを受け取ってしまうことが原因です。可視性タイムアウト値を増やし、他のインスタンスがメッセージを受信可能になるまでの猶予時間を延長することで、メッセージの重複処理を排除できます。
ロングポーリングは、SQSキューのメッセージが空である場合に設定された時間待機をする機能です。メッセージの重複受信を排除できる機能ではありません。
遅延キューは、メッセージをSQSキューに追加した後、指定時間が経ってからメッセージを配信できる状態にしたい場合に使用する機能です。
SQSキューを使用することでユーザからのリクエストと解析処理を非同期で進行することができます。さらに、ECSを用いることで異なるタイプのサーバ(解析処理)を容易にデプロイ・管理することができます。また、ECSの自動スケーリングを用いることで使用状況に応じたリソースのスケールイン・アウトも実現できます。
Route 53のシンプルルーティングポリシーを使用することで、ユーザからのリクエストを適切なサーバにルーティングすることはできますが、非同期な処理となりません。
Route 53の「フェイルオーバールーティングポリシー」は、通常時はプライマリに設定したリソースのIPアドレスを回答し、プライマリのリソースにヘルスチェックで異常が発生した場合は、セカンダリに設定したリソースのIPアドレスを回答します。
DynamoDBのグローバルテーブルは、DynamoDBテーブルを複数のリージョンにまたがって運用できるサービスです。指定したリージョンにDynamoDBテーブルが自動的にレプリケートされます。データのレプリケーションは通常1秒以内に完了し、リージョン間のデータ冗長化によって高可用性が確保されます。
Amazon Aurora Global Database
Amazon Aurora Global Database(Auroraグローバルデータベース)は、Auroraデータベースを複数のリージョンにまたがって運用できるサービスです。例えば、東京リージョンで稼働しているデータベースを大阪リージョンにも配置できるということです。Auroraグローバルデータベースを使用しても、ユーザーは二つのリージョンのデータベースを管理する必要はありません。データはプライマリとして稼働しているメインのリージョンからセカンダリリージョンへレプリケートされます。
Route 53のルーティングポリシーのうち「フェイルオーバールーティングポリシー」では、通常時にアクセスさせたいリソースをプライマリに設定し、プライマリに障害が発生した場合にアクセスさせたいリソースをセカンダリに設定します。通常時はプライマリに設定したリソースのIPアドレスを回答し、プライマリのリソースにヘルスチェックで異常が発生した場合は、セカンダリに設定したリソースのIPアドレスを回答します。このようにサービスを提供するリソースがプライマリからセカンダリへ自動的に切り替わる仕組みのことを「フェイルオーバー」といいます。
Amazon Simple Queue Service(SQS)はフルマネージドのメッセージキューイングサービスであり、サービス同士の橋渡しを担います。SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。
Amazon Simple Notification Service(SNS)はプッシュ型のメッセージングサービスです。SNSはプッシュ型なので、サブスクライバー(受信者)の状態に関わらずメッセージを配信します。
SQSとSNSを組み合わせると、SNSへメッセージを発行するだけで複数の送信先へ効率的に配信することが可能です。これにより、後続のアプリケーションは、自身の分野で必要な必要な問い合わせ情報のみを取得して処理することが可能になります。
また、SQSキューのメッセージは受信側が明示的に削除の指示をしない限り削除されません。受信側の処理中にエラーが発生した場合は削除が実行されず、メッセージはSQSキューに残ります。そして、エラーが解消されてから再処理することで、データの消失を防ぐことができます。
Amazon Auroraはフルマネージド型サービスであるAmazon RDS(Relational Database Service)で利用可能なデータベースエンジンです。データベースのスケーリング(拡張、縮小)、高可用性、バックアップなどはRDS(AWS)によって管理されます。また、Auroraはデータベースへの負荷に応じて動的にレプリカインスタンスを増減するAuto Scaling機能を備えています。平均CPUまたは平均接続数に任意の値を設定し(例:「CPU使用率 50%」など)、設定した値が維持されるようにレプリカインスタンスが調整されます。
AuroraはAWS Backupにも対応していますので、細かい頻度でバックアッププランを作成したり、ポイントインタイムリカバリを有効化できます。
Amazon SQS
・ユーザからのリクエストをAmazon SQSキューに格納する。解析処理用のサーバはコンテナ化してAmazon ECSへデプロイし、ECSからキューを読み込み処理を行う。ECSの自動スケーリングを有効にする
SQSキューを使用することでユーザからのリクエストと解析処理を非同期で進行することができます。さらに、ECSを用いることで異なるタイプのサーバ(解析処理)を容易にデプロイ・管理することができます。また、ECSの自動スケーリングを用いることで使用状況に応じたリソースのスケールイン・アウトも実現できます。
Lambda関数には実行時間の制限(1回につき最長15分)があり、数GBにまで達するデータを扱う場合、処理が完了できない可能性があります。
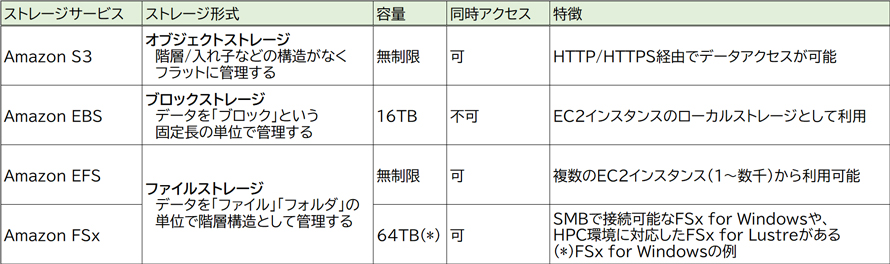
Amazon EBS
Amazon EBSは、EC2インスタンスの内部ストレージと同じように利用できるブロックストレージです。ユーザーは用意されたいくつかのボリュームタイプから用途に合ったものを選択して利用します。EBSボリュームはAZ内でレプリケートされ、高い耐久性(99.8%~99.999% )を実現させています。
Amazon S3は安価で耐久性が高く、保存容量が無制限のオブジェクトストレージサービスです。S3にアップロードされたデータはリージョン内の最低3か所のAZに保存され、非常に高い可用性(99.999999999%)を実現させています。

RDS for MySQLとAmazon Aurora MySQL互換エディション間では、標準的なインポート/エクスポートツールやスナップショットを使用してデータの移行を行うことができます。
DBスナップショットが存在する場合には、「データベースの移行」機能を使用してAmazon Auroraデータベースクラスタを作成することができます。
mysqldumpを使用したダンプファイルがある場合には、S3バケットにダンプファイルを配置し、そこからAmazon Auroraにデータをインポートすることができます。
AWSが提供する代表的なデータベースサービス
AWSが提供する代表的なデータベースサービスには以下があります。

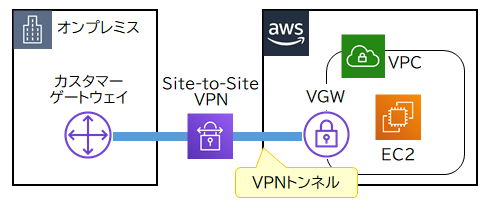
AWS Site-to-Site
AWS Site-to-Site VPNで使用する仮想プライベートゲートウェイ(VGW:Virtual Private Gateway)とVPNトンネルは、機器障害に対する高可用性を保つためにAWS側で冗長化されています。一方、カスタマーゲートウェイはオンプレミス内の機器なので、高可用性を保つにはAWSユーザ側で冗長化する必要があります。カスタマーゲートウェイを追加することで単一障害点(※)がない構成にできます。
・開発用VPCと本番用VPC間のVPCピアリングを複数設定して、相互通信の可用性を高める
2つのVPC間で同時に複数のVPCピアリングを持つことはできません。また、VPCピアリングはAWS側で管理されており単一障害点は存在せず、ユーザ側で冗長性を意識する必要はありません。
・本番用VPCのDirect Connectの代わりに、Site-to-Site VPNを設定する
本番用VPCの通信のために既に複数のDirect Connectが構成されており、単一障害点は存在しません。
・開発用VPCのSite-to-Site VPNのVPNトンネルを複数設定し、VPN接続の冗長性を確保する
VPNトンネルの回線はAWS側で冗長化されており、ユーザ側で冗長化を意識する必要はありません。
カスタマーゲートウェイデバイスが使用できなくなった場合に接続が失われるのを防ぐために、2 番目のカスタマーゲートウェイデバイスを追加して、VPC および仮想プライベートゲートウェイへの 2 番目の Site-to-Site VPN 接続を設定できます。冗長な VPN 接続とカスタマーゲートウェイデバイスを使用すれば、1 つのデバイスでメンテナンスを実行しながら、2 番目の VPN 接続を通してトラフィックの送信を継続することができます。2 つの VPN 接続は、以下の図のようになります。各 VPN 接続には、独自のトンネルと独自のカスタマーゲートウェイがあります。
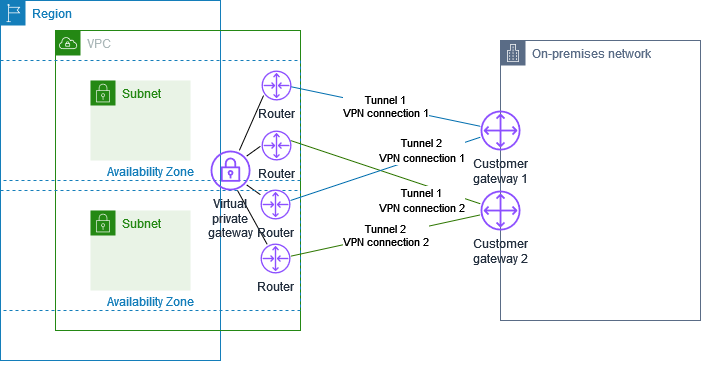
このシナリオでは、次の操作を行います。
2 つ目のカスタマーゲートウェイデバイスを設定します。どちらのデバイスも、同じ IP 範囲を仮想プライベートゲートウェイにアドバタイズする必要があります。当社は BGP ルーティングを使用してトラフィックのパスを特定しています。1 つのカスタマーゲートウェイデバイスが失敗した場合、仮想プライベートゲートウェイが、すべてのトラフィックを動作中のカスタマーゲートウェイデバイスに送信します。
同じ仮想プライベートゲートウェイを使用し、新しいカスタマーゲートウェイを作成して、2 番目の Site-to-Site VPN 接続をセットアップします。2 番目の Site-to-Site VPN 接続用カスタマーゲートウェイの IP アドレスは、パブリックにアクセス可能である必要があります。
デッドレターキュー
Amazon SNS(Simple Notification Service)では、SNSトピックからメッセージの配信に失敗した場合、通常はメッセージを破棄してしまいます。メッセージの破棄を防ぐには、配信不能メッセージをAmazon SQSのデッドレターキューに送信するようにサブスクリプションを設定します。デッドレターキューに保持されたメッセージをLambda関数がポーリングすることで、SNSトピックから配信された全てのメッセージがLambda関数で処理されるようになります。
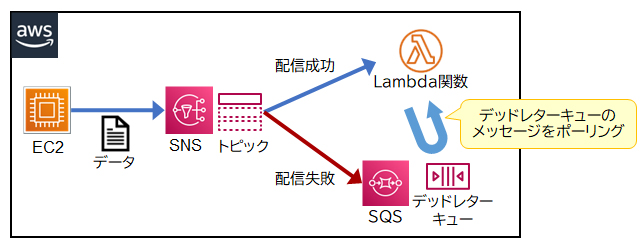
SQSのデッドレターキューは、エラーが一定の回数に達したメッセージを隔離するためのキューです。SNSがメッセージ配信に失敗した場合、配信不能メッセージの送信先としても利用できます。
下記はサブスクリプションのデッドレターキュー設定画面です。
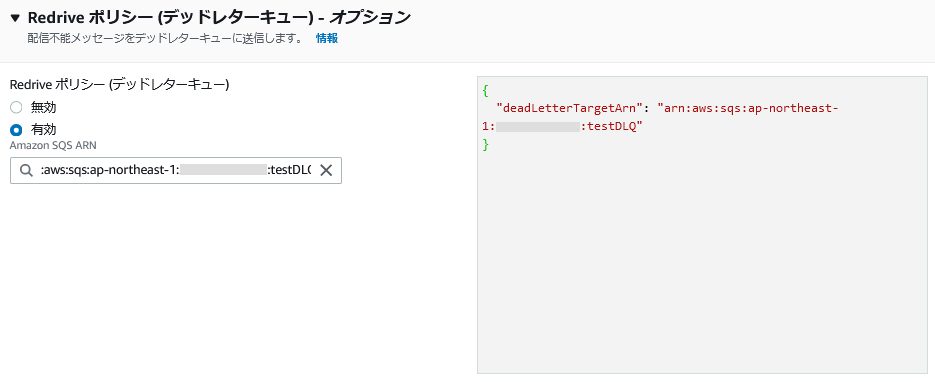
配信不能メッセージをAmazon SQSのデッドレターキューに送信する。Lambda関数でキューのメッセージを処理することは可能です。
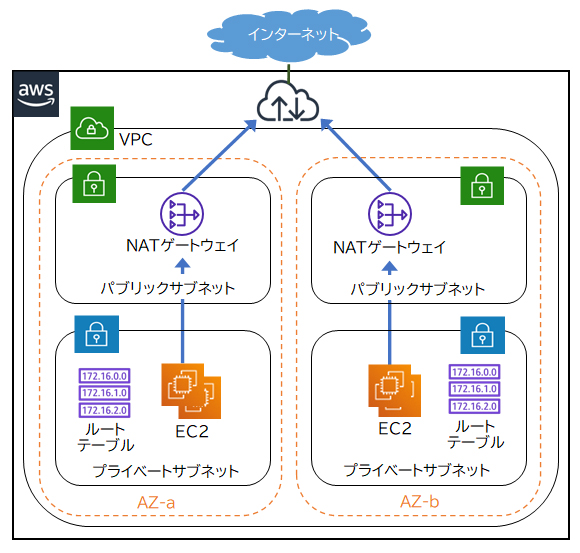
NATゲートウェイ
NATゲートウェイは、プライベートサブネットからインターネットへの通信を可能にするIPv4専用の機能です。NATゲートウェイはプライベートサブネット内リソースからインターネットへの接続開始要求は通しますが、インターネットからプライベートサブネット内リソースへの接続開始要求は通しません。
プライベートサブネットからインターネットへアクセスするには、NATゲートウェイをパブリックサブネット内に作成し、プライベートサブネットのルートテーブルにターゲットがNATゲートウェイのルーティングを設定します。
NATゲートウェイはAWSによってAZ内で冗長化されており、NATゲートウェイの機器障害時やトラフィック増加時でも継続して利用できます。ただし、AZに障害が発生した場合には利用できなくなるため、さらに可用性を高める場合は複数のAZにそれぞれNATゲートウェイを配置する必要があります。
本設問では、アーキテクチャ全体が高可用性を確保できる構成を要求されているので、複数のAZ内のパブリックサブネットにNATゲートウェイをそれぞれ配置します。各NATゲートウェイへのルーティングの設定も必要なので、プライベートサブネットごとにルートテーブルを設定します。
SNS FIFO
・SNSトピックをFIFOトピックに変更する
→FIFOトピックはメッセージが順序付けられてAmazon SQSのFIFOキューへ配信する機能です。
配信不能メッセージを処理させることとは無関係なので、誤りです。また、FIFOトピックではメッセージの配信先に指定できるのはSQSのみで、Lambda関数は指定できません。
Kinesis Data Streams
Kinesis Data Streamsは外部から送信されるストリーミングデータを収集するサービスです。センサーなどが生成したストリーミングデータをKinesis Data Streamsのストリームへ送信し、ストリーム上のデータは分析や機械学習などを行う他のAWSサービス(例えばLambda、Data Firehose、Managed Service for Apache Flinkなど)がリアルタイムに読み取って処理します。
収集したデータを分析・加工するには「AWS Lambda」を利用します。Lambdaはサーバーレスでプログラムのコードを実行できるサービスです。サーバーレスとはAmazon EC2などのサーバーを必要とせず、リクエスト発生時にだけプログラムが実行されるアーキテクチャのことです。
LambdaではKinesis Data Streamと連携し、ストリーミングデータを処理できます。Lambda関数の作成時には、Kinesisのストリーミングデータを利用するテンプレートも用意されています。
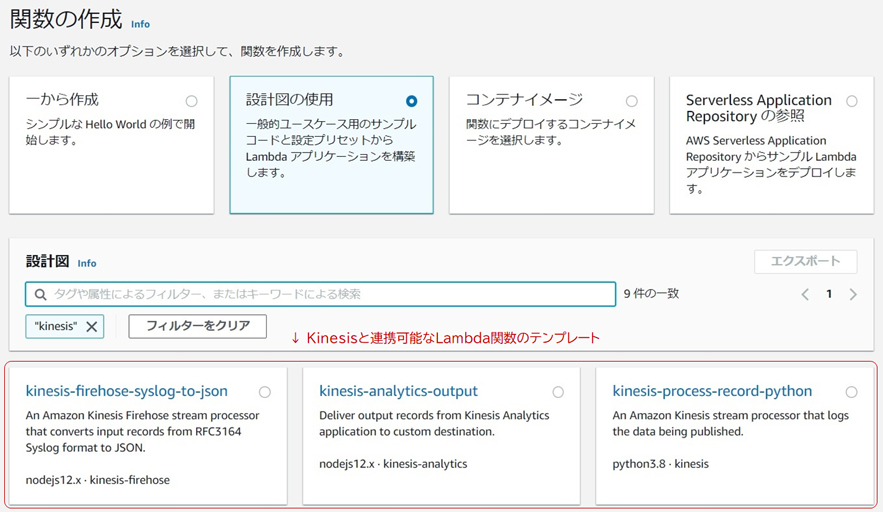
・Amazon Simple Queue Service(SQS)でデータ受信と処理を行うコンポーネントを接続する。メッセージ取得時は、ロングポーリングで取得する
→Amazon SQSはフルマネージドのメッセージキューイングサービスであり、サービス同士の橋渡しを担います。また、ロングポーリングとは、ポーリング(メッセージキューに対する問合せ)した際にメッセージが空である場合は一定時間待ち合わせる設定をいいます。SQSでコンポーネント間を接続することで、高負荷のために処理しきれなくなるという問題を解消できることはありますが、ロングポーリングはAPIコール数を減らすコスト削減の設定であり、本設問の問題を解消しません。
・データ受信にはAmazon Data Firehoseを利用し、データの処理にはAWS Glueを使用する
→Glueは複数のデータソースからデータを抽出し、変換・統合したデータをターゲットへ格納するサービスです。
Data Firehoseはリアルタイムデータの受信に適していますが、Glueはバッチ処理に適しておりリアルタイムのデータ処理には適していないので、誤りです。なお、Data FirehoseからLambda関数を呼び出してデータを処理する方法であれば、設問の要件を満たせます。
Kinesis Data Streamsでは、ストリーミングデータを「データレコード」という単位で処理します。データレコードには、データそのものに加えて「パーティションキー」「シーケンス番号」が含まれます。
・パーティションキー … どのシャード(後述)で処理するかを決めるもの。プロデューサー側で設定する
・シーケンス番号 … シャードごとに一意の番号。シャード内のデータレコードの順序性が保証される
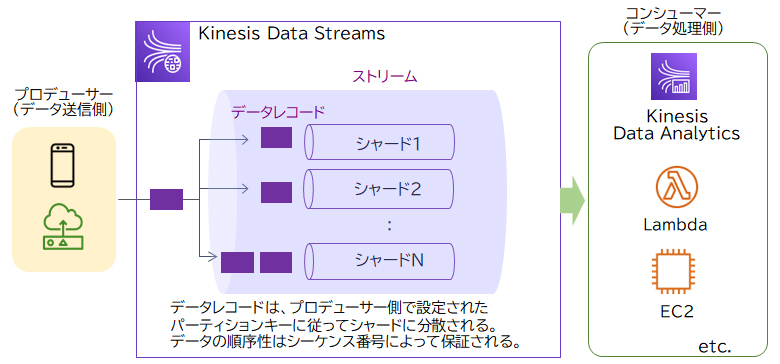
データレコードは「シャード」に分散され処理されます。シャードは、ストリームで処理できるデータの容量を決めるもので、シャードが多いほど並列処理の数が増えてスループットが上がります。
デバイスごと、データを取得した順に蓄積する場合、Kinesis Data Streamsによるストリーミングデータの受信を行うのが適切です。プロデューサー側で、デバイスごとに異なるパーティションキーを設定することにより、処理するシャードを分けることができます。各シャードではシーケンス番号により順序性が保証されます。
また、データウェアハウスへの配信は、Data FirehoseによりRedshiftと連携できるため、Kinesis Data Streams + Data Firehoseでデータを処理するのがよいでしょう。
なお、データウェアハウス(DWH:Data WareHouse)とは複数のシステムからデータを収集・統合・蓄積し、分析に使用するデータベースのことです。AWSではRedshiftが該当します。
Amazon ECS
Amazon ECS(Elastic Container Service)はコンテナを実行、管理するサービスです。「コンテナ」とはアプリケーションと実行環境をパッケージ化する仮想化技術の一種のことです。
コンテナはマイクロサービスの実現に適しています。ひとつのサービスをひとつのコンテナで実行することで効率的にマイクロサービスを構築できます。
Amazon SQSはフルマネージドのメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。Amazon SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。

サービスAはクライアントからのリクエストを受け、キュー(queue)と呼ばれる領域にリクエスト(メッセージ)を投入します。サービスBはキューからメッセージを取得し、処理します。
メッセージキューを利用すると、お互いのサービスがそれぞれの状況に関係なく(非同期で)処理を進行できるため、サービス間の結合度が低くなります。このように、システムを構成するサービスやコンポーネント間の結合度や依存度を低くし、独立性を高めることを「疎結合」または「デカップリング」といいます。
サービス間の結合度を低くすると以下のようなメリットがあります。
・関連するサービスの負荷や処理状況に引きずられずに自身の処理を進行できる
・関連するサービスで障害が発生した場合やアップデートなどの際に影響を受けずに済む
SQSはこのようにサービス同士を橋渡しする役割を持つAWSサービスです。
Amazon SQS
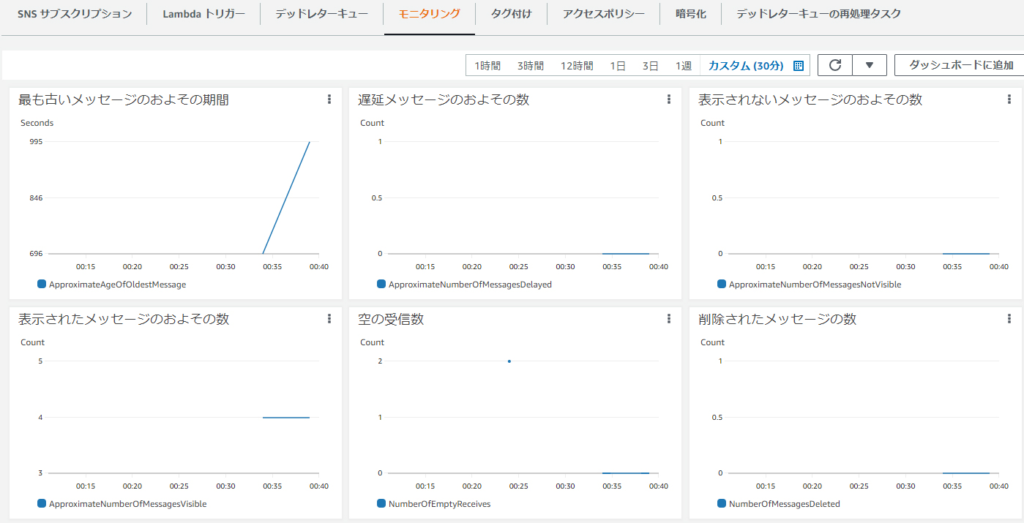
SQSのメッセージキューの状態はAmazon CloudWatchにより取得・監視できます。SQSのメトリクスには以下のようなものがあります。以下はマネジメントコンソールの「モニタリング」タブの参照例です。
また、Auto Scalingにおけるスケーリングの発生条件のうち「動的スケーリング」は、CPUやネットワークなどのパフォーマンスの負荷状況に応じて、自動的にスケールアウト(リソースの増加)/スケールイン(リソースの削減)を実施します。動的スケーリングを利用するには、スケーリングの発生条件となるメトリクスと、スケールアウト/インのアクションを「動的スケーリングポリシー」に設定します。
SQSのメッセージキューの状態に応じてAuto Scalingグループをスケーリングすることができます。メッセージキュー内にメッセージが蓄積した場合にAuto Scalingで処理するインスタンス数を増やす(スケールアウトする)ことで処理速度を一定に保ちます。
SQSのメッセージキューAuto Scalingの条件にすると、例えば以下のようなAuto Scalingを実現できます。
– メッセージキュー内のメッセージ数が100を超えたら1台追加、300を超えたら2台追加する(ステップスケーリング)
– メッセージキュー内のメッセージ数とメッセージの処理時間を計算し、平均応答速度を一定に保つ(ターゲット追跡スケーリング)
「最も古いメッセージの期間(ApproximateAgeOfOldestMessage)」によりキュー内で削除されないまま残っているメッセージの経過時間や、「キューから取得可能なメッセージ数(ApproximateNumberOfMessagesVisible)」によりキュー内に存在するメッセージの数などを取得します。
Auto Scalingにおけるスケーリングの発生条件のうち「動的スケーリング」は、CPUやネットワークなどのパフォーマンスの負荷状況に応じて、自動的にスケールアウト(リソースの増加)/スケールイン(リソースの削減)を実施します。動的スケーリングを利用するには、スケーリングの発生条件となるメトリクスと、スケールアウト/インのアクションを「動的スケーリングポリシー」に設定します。
メトリクスとして取得したSQSのメッセージキューの状態に応じて、Auto Scalingグループをスケーリングすることができます。メッセージキュー内にメッセージが蓄積した場合にAuto Scalingで処理するインスタンス数を増やす(スケールアウトする)ことで処理速度を一定に保ちます。
DynamoDBのS3へのエクスポート機能
DynamoDBのS3へのエクスポート機能は、既存のテーブルデータを任意のS3バケットに直接エクスポートする機能です。ユーザはこの機能のために独自のアプリケーションを用意したり、追加のコードを記述したりする必要はありません。また、この機能を使用したデータのエクスポートでは、対象のテーブルに設定されたRCUを消費せず、テーブルの可用性やパフォーマンスにも影響を及ぼさないという点が大きなメリットです。
なお、この機能は、内部的にDynamoDBの継続的バックアップの機能(ポイントインタイムリカバリの前提となる機能)を使用しているため、対象のテーブルのポイントインタイムリカバリを有効にしておく必要があります。
Global Accelerator
Global Acceleratorは、ユーザーからAWSリソースまでのアクセス経路をAWSネットワークを利用して最適化するサービスです。ユーザーからWebサーバーまでのネットワーク遅延は軽減できますが、リクエスト増加に伴うWebサーバーやデータベースの負荷は軽減できません。
Amazon EFS
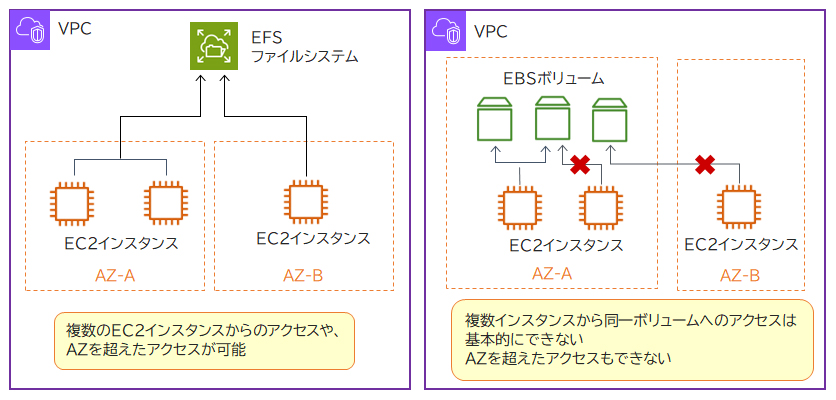
Amazon EFS(Elastic File System)はNFS(Network File System)プロトコルをサポートするファイルストレージサービスです。EFSはNFSに対応したAWSサービスおよびオンプレミス(自社運用)のシステムから利用できます。
EFSは異なるAZのEC2インスタンスからもアクセスできます。
ACIDとは、原子性(Atomicity)、一貫性(Consistency)、独立性(Isolation)、耐久性(Durability)を意味する言葉で、更新処理中に中途半端なデータが書き込まれないことや、並行処理がそれぞれ独立して動作する(互いに干渉しない)ことなど、処理の信頼性を保証する性質をいいます。
EFSはデータ更新時の操作結果が即時に他のデータへ反映され、操作直後でも最新のデータが参照できる「強力な整合性」を採用しています。また、複数のAZで冗長化されているので高い耐久性があります。EFSは最大数千のEC2インスタンスから同時アクセス可能な、ACID特性のあるストレージです。
EBSは基本的に複数のインスタンスからアタッチできません。一部のボリュームでは複数インスタンスからのアタッチが可能なマルチアタッチ機能に対応していますが、異なるAZ間ではアタッチできません。
Amazon ElastiCacheはインメモリデータベースサービスです。非常に高速なアクセスが可能でキャッシュなど一時的なデータ保存に適しています。大量の参照/更新に対して高パフォーマンスな対応ができますが、結果整合性を採用しているのでノード間でデータに相違が生じる場合があります。
また、Memcached型はデータの永続保持やバックアップ機能はないので、障害や再起動などが発生した場合はデータが残りません。Memcached型のAmazon ElastiCacheはACID特性ではありません。
ALB
ALBではHTTP、HTTPSをサポートしています。また、WebSocketや、同一インスタンス内の複数ポートへの負荷分散、ホストベースやパスベース、URLクエリ文字列でのルーティングに対応しています。
パスベースのルーティングとは、クライアントがリクエストした接続先URLのパスに従ってルーティングできる機能のことです。例えば、クライアントの接続先URLが「http://www.example.com/web1/」の場合はWebサーバー1にアクセスさせて、「http://www.example.com/web2/」の場合はWebサーバー2にアクセスさせることができます。
ALBのターゲットにEC2インスタンスとオンプレミス上のサーバーを指定することで、AWSとオンプレミス間でルーティングが可能になります。ALBからオンプレミスまではAWS VPNを経由します。
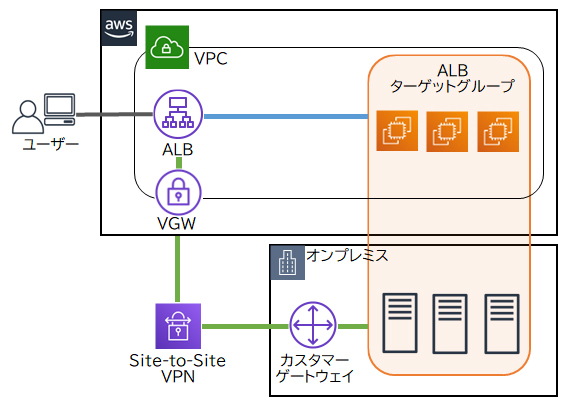
・ALBを2つ配置し、1つはターゲットにEC2インスタンス、もう1つはオンプレミス上のサーバーを指定する。ALBでパスベースのルーティングを設定する。
→ユーザーからのアクセスをEC2インスタンスとオンプレミス上のサーバーに振り分けるには、1つのALBでルーティングの設定をします。
・ALBを2つ配置し、1つはターゲットにEC2インスタンス、もう1つはオンプレミス上のサーバーを指定する。Route 53でURLパスに従ってALBへルーティングする。
→Route 53ではURLパスに従ったルーティングはできません。また、ユーザーからのアクセスをEC2インスタンスとオンプレミス上のサーバーに振り分けるには、1つのALBでルーティングの設定をします。
Amazon API Gateway
Amazon API Gatewayは、AWSサービスと連携するAPIの作成や管理ができる機能です。S3の静的Webサイトホスティングの入力フォームから受け取ったデータを、SQSのキューに投入するという橋渡しのような動作も可能です。

災害復旧を考慮したマルチリージョンの利用
Route 53の「フェイルオーバールーティングポリシー」は、通常時はプライマリに設定したリソースのIPアドレスを回答し、プライマリのリソースにヘルスチェックで異常が発生した場合は、セカンダリに設定したリソースのIPアドレスを回答します。Route 53のフェイルオーバールーティングポリシーをマルチリージョンで設定することで、災害時には自動的にセカンダリリージョンへ切り替えられます。
EC2インスタンスにアタッチされるEBSボリュームは、データのバックアップ手段としてスナップショット機能を備えています。スナップショット(snapshot)とはある時点のストレージの状態(保存されているファイル群など)を取得したもののことです。スナップショットを別リージョンへコピーすることでリージョン間バックアップが作成可能です。RDSにもEBSと同様にスナップショット機能があります。マルチリージョンのリードレプリカを利用するよりも安価にリージョン間バックアップが作成可能です。
災害復旧(DR:Disaster Recovery)プランで用いられる「RPO(Recovery Point Objective:目標復旧時点)」とは、障害発生時にデータを復旧させる時点のことで、障害が発生した際にどの時点までのデータを復旧させるかという指標です。「RTO(Recovery Time Objective:目標復旧時間)」とは、どのくらいの時間で(いつまでに)復旧させるかという指標で、サービスやシステムが許容できる停止時間を意味します。
設問の場合、半日毎にEBSやRDSのスナップショットを作成し、セカンダリリージョンへコピーすることで、RPO(目標復旧時点)の12時間を満たせます。また、EC2インスタンスもRDSデータベースもスナップショットを元に復旧し、Route 53で自動的にフェイルオーバーできるので、RTO(目標復旧時点)の3時間も満たせます。
・ALBでリージョン間の負荷分散を実施し、ヘルスチェックを設定する
→ALBではリージョン間の負荷分散はできません。
NLB
NLBはレイヤー4(トランスポート層)で負荷分散を行い、TCP、UDP、TLSをサポートしています。NLBのターゲットにオンプレミスのサーバーのIPアドレスを指定することで、クライアントからNLBに接続し、AWS VPNを経由してオンプレミス上のサーバーに負荷分散できます。また、NLBはElastic IPアドレスを割り当てられるので、ユーザーはNLBの固定IPアドレスへアクセスします。 NLBはターゲットグループ内の各ターゲットが正常に動作しているかを定期的に確認します。ターゲットから正常に応答が返ってくればNLBからリクエストをターゲットへ転送し、異常があれば転送を停止します。複数台のサーバーをターゲットグループに登録することにより、1台のサーバーに障害が発生しても、他の正常なサーバーへリクエストが転送されるので、システムの可用性が高くなります。
NLBはターゲットグループ内の各ターゲットが正常に動作しているかを定期的に確認します。ターゲットから正常に応答が返ってくればNLBからリクエストをターゲットへ転送し、異常があれば転送を停止します。複数台のサーバーをターゲットグループに登録することにより、1台のサーバーに障害が発生しても、他の正常なサーバーへリクエストが転送されるので、システムの可用性が高くなります。
既存のEC2インスタンスからAMIを作成し、複数のEC2インスタンスで構成されるAutoScalingグループを設定する。ALBを構成し、AutoScalingグループをターゲットグループとして設定する
Auto ScalingとALBを組み合わせることで、EC2インスタンスの動的なスケーリングと負荷分散が実現できます。ウェブサイトの高可用性とパフォーマンスの維持に有効です。
・画像や動画はAmazon EFS上に格納し、各EC2インスタンスからマウントする
→Amazon EFSは同時アクセスが可能なフルマネージド型のファイルストレージサービスで、複数のインスタンスから参照されるデータを集約して格納するのに適しています。また、デフォルトで複数のAZにまたがってサービスを提供しているため、単独AZの障害時にも影響を受けず、高い可用性を実現できます。
SNSでは「FIFOトピック」を作成できます。SNS 標準トピックではメッセージの配信順序は考慮されませんが、「SNS FIFOトピック」ではメッセージが順序付けられて「SQS FIFOキュー」に配信されます。メッセージが必ず1回だけ配信されるようになるので、順序付きの処理や重複を避ける必要があるケースで使用します。なお、FIFO(First In First Out)とは「先入れ先出し」の意味で、メッセージを受け取った順番に配信します。
本設問のケースでは、
・第1段階の決済処理の完了後に、第2段階の処理を行う
・第2段階の2つの処理(伝達処理とデータベース登録処理)は並列で行う
という点から、SNSとSQSによる連携処理を行うのが適切です。
また、
・注文は必ず受注した順番で処理する
・複数回処理されてはならない(重複排除)
という要件から、SNSのFIFOトピックと、SQSのFIFOキューを採用します。
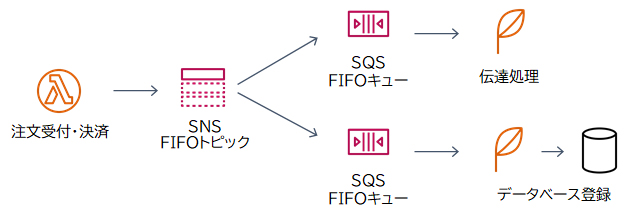
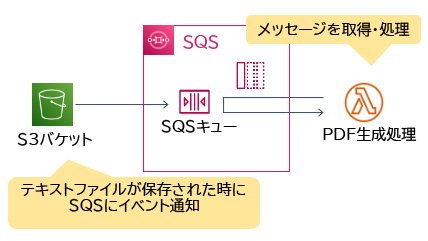
S3イベント通知は、S3バケットに発生したイベント(オブジェクトの作成や削除など)をトリガーに通知を行う機能です。通知はLambda関数、SQSキュー、SNSトピックに送信できます。
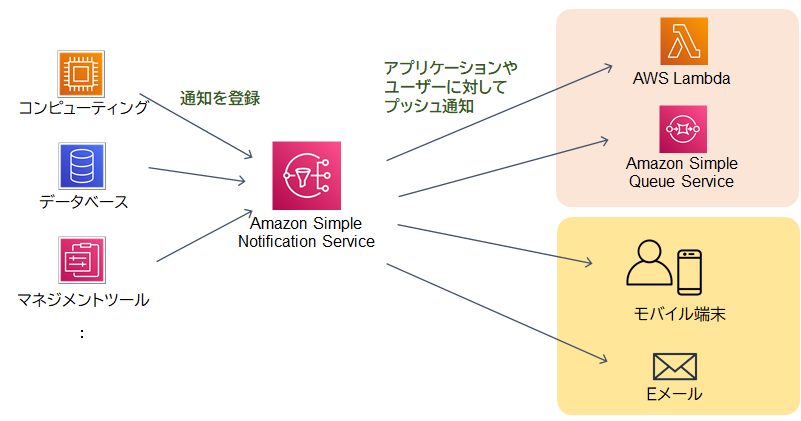
Amazon SNSはフルマネージドのメッセージングサービスです。「メッセージ」とはシステム間を連携する通知やデータのことで、EメールやSMS、Lambda関数、Amazon SQSを通して、複数のアプリケーションやユーザーに対して同時にメッセージを配信します。Amazon SNSはプッシュ型なので、サブスクライバー(購買者)の状態に関わらずメッセージを配信します。
Amazon SQSはフルマネージドのメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。Amazon SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。
SNSとSQSを組み合わせると「ファンアウト」構成を実装できます。ファンアウトとは、一つのメッセージを複数の送信先に配信し、それぞれが並列に処理を実行する仕組みのことです。これにより、効率的な分散処理を実現できます。
SQSのみで実装した場合、並列化の処理はリクエスト発行者側で制御しなければなりません。SNSと連携すると、SNSへメッセージを発行するだけで並列処理を実現します。並行処理の制御などの考慮が不要になることにより、コンポーネント間の結合度をより少なく(疎結合に)構成できます。
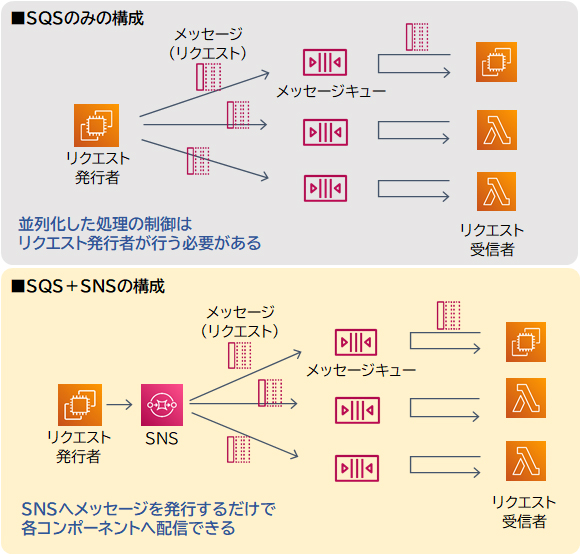
設問の例では、S3バケットにPDFファイルが保存されるたびに、Lambda関数を使用して注文情報をAmazon SNSに配信します。SNSトピックは、各アプリケーションに対応する複数のSQSキューにメッセージを配信します。これにより、各アプリケーションは他のアプリケーションの進行状況に影響を受けずに並列に処理できます。

SNSからのメッセージをSQSのメッセージキューで受け取るには、対象のキューをSNSトピックへサブスクライブ(購読)します。1つのイベントに対して並列に処理したいようなケースでは、アプリケーションA、B用のSQSキューを作成し、それぞれをSNSトピックへサブスクライブするのが適切です。
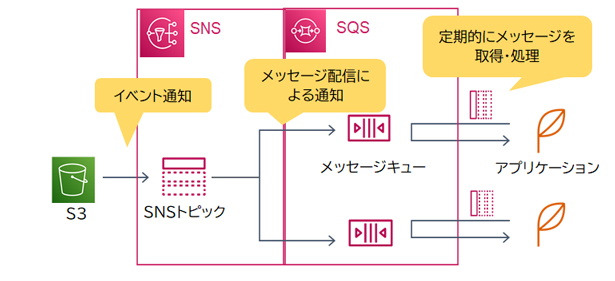
1つの処理結果を複数のアプリケーションへ通知する必要があるためSNSトピックを作成します。また、一部のアプリケーションでは通知を受信できるようになるまでばらつきがあるため、受信者が任意のタイミングで通知を受け取ることができるSQSのメッセージキューと合わせて構成します。このように、SNSとSQSを組み合わせてメッセージを複数の送信先に配信する構成のことを「ファンアウト」といいます。
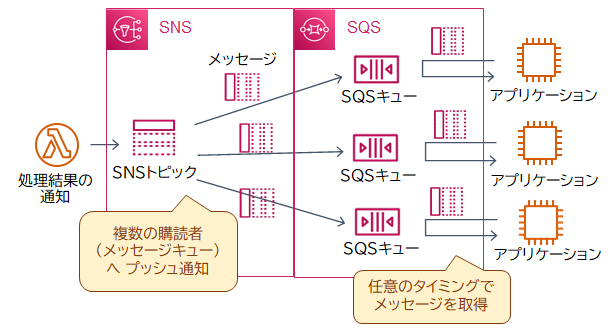
さらに「同じ処理を複数回実行してはならない」という重複排除の要件を満たすには「SNS FIFOトピック」を利用します。SNS 標準トピックではメッセージの配信順序は考慮されませんが、SNS FIFOトピックではメッセージが順序付けられて「SQS FIFOキュー」に配信されます。メッセージが必ず1回だけ配信されるようになるので、順序付きの処理や重複を避ける必要があるケースで使用します。なお、FIFO(First In First Out)とは「先入れ先出し」の意味で、メッセージを受け取った順番に配信します。
ALB(Application Load Balancer)
ALB(Application Load Balancer)はAWSが提供する負荷分散サービスです。配下に持つターゲット(本設問ではEC2インスタンス)に対して、トラフィックを分散させることができます。
ALBには、各ターゲットが正常に動作しているか定期的に確認するヘルスチェックの機能があり、この結果に基づいて、正常なEC2インスタンスにのみ処理を振り分けることができます。
この機能を用いることで、一部のサーバに障害が発生した場合でも他の正常なサーバに自動的に処理が振り分けられ、ユーザにエラーが返されたりサービスが停止したりすることを抑制できます。
・Route 53の加重ルーティングポリシーを使用し、全てのインスタンスに同じ割合の重みづけを行い、トラフィックを均等に振り分ける
→ 加重ルーティングポリシーを使用することで、あらかじめ設定しておいた重みづけの割合に応じてトラフィックを分散させることができますが、これだけではインスタンスの状態に応じた動的な振り分けは行えない
・Route 53のフェイルオーバールーティングポリシーを使用し、プライマリ/セカンダリの設定を行い、ヘルスチェックの結果プライマリのインスタンスが異常と判断された場合には、自動的にセカンダリのインスタンスにフェイルオーバーさせる
→フェイルオーバールーティングポリシーは、1つのプライマリと1つのセカンダリの構成でフェイルオーバーを行うことを目的とした機能です。複数インスタンスが稼働している状況における可用性の高い構成としては、ALBを用いた振り分けの方が適切です。
EBS
EBSボリュームは基本的に一つのEC2インスタンスにしかアタッチすることができません。Auto Scalingにより新たに追加されたEC2インスタンスとのデータの同期を実現するには運用上の手間がかかります。また、容量制限もある
バックアップ
RDSにおける自動バックアップの保持期間は最大で35日です。35日を超えてスナップショットを保持したい場合は以下の方法があります。
– AWS Backupでバックアッププランを作成する
– 手動でスナップショットを取得する
手動で取得したスナップショットには保持期間の上限がありません。
– 自動バックアップで取得したスナップショットをS3バケットへ手動でコピー(エクスポート)する
S3バケットへのコピーは、RDSのスナップショット管理画面やAWS CLIなどから行います。
API Gateway Canaryリリース
API Gatewayでは、「ステージ」という概念を使用して、APIの異なるバージョンや開発段階を管理します。これにより、開発、テスト、本番などの異なる環境でAPIを個別に管理できます。
Canaryリリースは、新しいバージョンのAPIを段階的にリリースする方法です。まず、既存の本番ステージに新しいAPIバージョンをデプロイし、一部のトラフィックを新しいバージョンに向けます。例えば、初めは20%のトラフィックを新バージョンに割り当てます。新バージョンが安定して動作することが確認されたら、トラフィックの割合を徐々に増やしていき、最終的には全トラフィックを新バージョンに移行します。もし問題が発生した場合は、すぐに元のバージョンに戻すことができます。Canaryリリースを利用することで、リスクを分散し、ユーザーへの影響を最小限に抑えることができます。
[API GatewayでのCanaryリリースのイメージ図]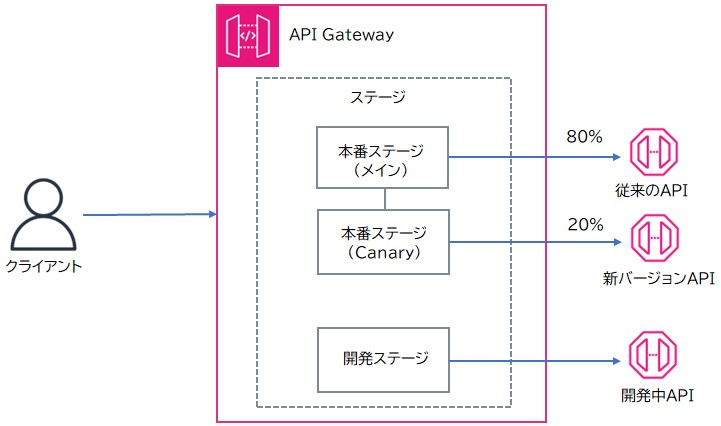
Amazon SQS
Amazon SQSはフルマネージドのメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。
SQSを使用することで、後続の処理(Lambda関数)に問題が発生したり、メンテナンスのために一時停止させたりした場合でも、処理すべき通知をキューに保持して、問題が解消されてから再実行することができます。また、一度に大量のリクエストが発生した場合でも、SQSキューを介することで、後続の処理に対する負荷を軽減できるなど、高い可用性と耐障害性を実現することができます。
S3のイベント通知は、S3バケットに発生したイベント(オブジェクトの作成や削除など)をトリガーに通知を行う機能です。通知先はLambda関数、SQSキュー、SNSトピック、EventBridgeです。この機能を使用することで、他のサービスやアプリケーションを介することなく、S3バケットから直接SQSキューへ通知を送ることができます。
Lambda関数側のトリガーの設定で、SQSキューをソースとして設定すると、Lambda関数はSQSキューをポーリングし、SQSキューにメッセージが入るとそれを処理します。
これらのサービスを組み合わせることで、高い可用性と耐障害性を備えたシンプルでメンテナンスのしやすい疎結合なシステムを構築することができます。
Amazon Route 53
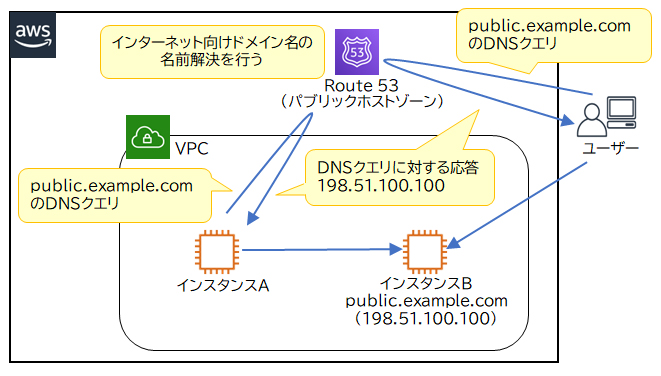
Amazon Route 53は、AWSが提供するマネージドなDNS(Domain Name System)運用サービスです。Route 53は非常に高い可用性と信頼性を備えており稼働率100%が保証されています。また、非常に柔軟なDNSサービスであり、AWS上で運営しているサービスだけでなく、オンプレミスサーバーなどAWS外のリソースに対しても使用することができます。
Route 53へのDNSサービスの移行は以下の手順で行われます。
●ステップ1: Route 53でパブリックホストゾーンの作成
Route 53ではゾーン情報を「ホストゾーン」で管理します。管理対象となるドメイン名がホストゾーンの名前になります。パブリックホストゾーンは公開インターネット向けの設定です。
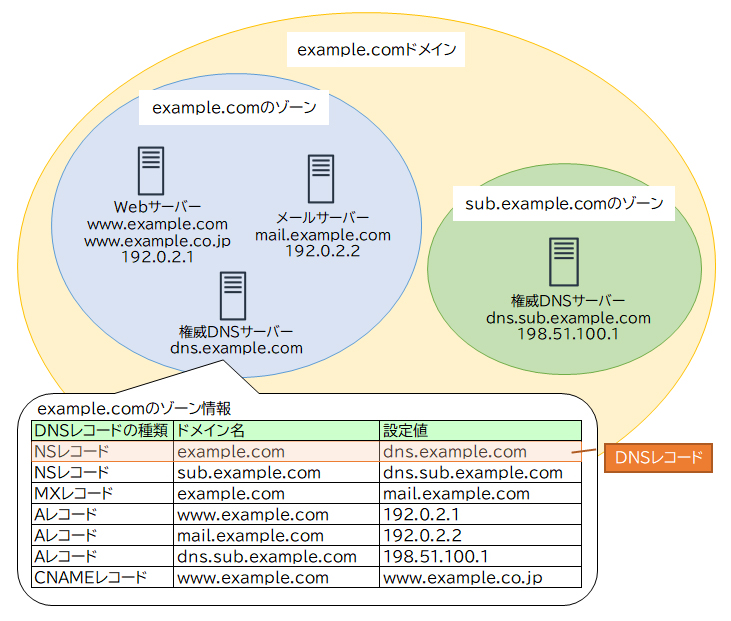
●ステップ2: 既存のDNSレコードの移行
ゾーンファイルをインポートして、既存のDNSプロバイダーにある全てのDNS情報をRoute 53に移行します。
●ステップ3: ドメインのネームサーバーの更新
既存のDNSプロバイダーのネームサーバーからRoute 53のネームサーバーに情報を更新します。
Route 53リゾルバーは、AWS内で実行されているリソースと、オンプレミスのデータセンターや他のクラウド環境との間でDNSクエリのルーティングと応答が可能になるサービスです。内部トラフィックの管理に有効ですが、外部向けのDNSパフォーマンス問題には対応していません。
既存のDNSプロバイダーとのハイブリッドセットアップを構築し、Route 53をセカンダリDNSとして導入する。これは冗長性を高める方法であり、既存のプロバイダーに問題が発生した際にセカンダリDNSがバックアップとして機能します。しかし、パフォーマンスの低下を直接解決するものではありません。
ALBのヘルスチェック
ALBのヘルスチェックは自ALB配下のインスタンスに対して応答確認をします。
複数リージョンを跨いだALB間のフェイルオーバーはできない。
Amazon SQS
Amazon SQSはフルマネージドのメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。Amazon SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。
サービスAはクライアントからのリクエストを受け、キュー(queue)と呼ばれる領域にリクエスト(メッセージ)を投入します。サービスBはキューからメッセージを取得し、処理します。
SQSがメッセージを配信したとき、SQSキュー内のメッセージは自動的に削除されません。受信側が、メッセージを正常に処理したあとにSQSキューから削除します。受信側の処理中にエラーが発生した場合は削除が実行されず、メッセージはSQSキューに残ります。SQSはメッセージを最長14日間保持できます。
本設問のケースでは、RDSデータベースがSQSキューへ直接ポーリングすることはできないため、新規にLambda関数を作成します。Lambda関数はSQSキューからデータを取得し、RDSデータベースへ保存します。Lambda関数がRDSデータベースへのアクセスに失敗した場合、SQSキューのメッセージは削除されず、データベースが利用可能になったときに、Lambda関数が再処理することでデータの損失を防止します。
Amazon Route 53
Amazon Route 53における7種類のルーティングポリシーのうち、シンプルルーティングポリシー以外はヘルスチェックが利用できます。Route 53のヘルスチェックは、ドメイン名に対応するリソースが正常に動作しているかを定期的に確認します。その結果、正常であったリソースのIPアドレスのみDNSクエリの回答とします。複数値回答ルーティングポリシーとフェイルオーバールーティングポリシーはヘルスチェックの結果に基づいて回答するので、ヘルスチェックの設定が必須です。
ALBのヘルスチェックは自ALB配下のインスタンスに対して応答確認をします。
複数リージョンを跨いだALB間のフェイルオーバーはできない.。
CloudWatchの監視アラートはRoute 53のフェイルオーバールーティングポリシーに適用できない。
ALBはパブリックDNSに対応するIPアドレスが公開されておらず、Aレコードを作成できない。
EKS
EKSでは、以下の機能を用いることで、実行中のアプリケーションの負荷状況に応じたポッドやノードのスケールアウト/インを実現することができます。
■ Horizontal Pod Autoscaler (HPA)
CPU使用率やメモリ使用量といったメトリクスに基づきポッドの数を自動的に増減させる水平方向のスケーリング機能です。
■ Cluster Autoscaler
ノード(実行環境)の数を自動的に増減させるスケーリング機能です。HPAによりポッドのスケールアウトが発生した時に、追加されるポッドを実行するだけのリソースが既存のノードに不足していると、追加のポッドは起動できず待ち状態(Pending)になります。このような場合に、Cluster Autoscalerは新しいポッドが必要とするリソースに基づいて新しいノードを追加し、逆に不要なノードがあればそれらのノードを終了します。
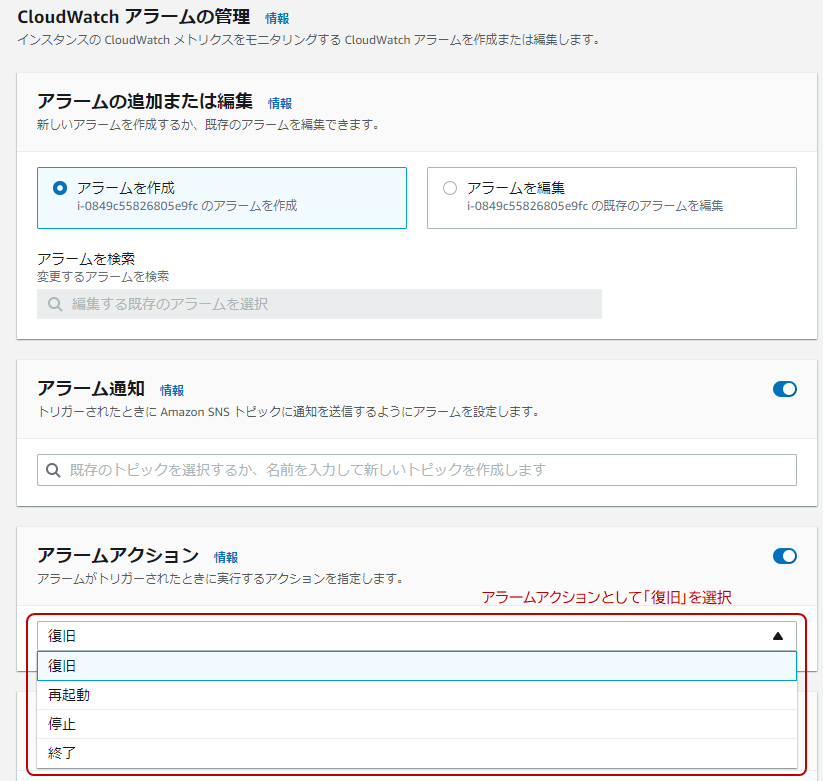
Amazon CloudWatchでは、監視するAWSリソースの情報(メトリクス)に対してアラームとアクションを設定できます。例えば「EC2インスタンスのCPU使用率が80%を超えたとき」というアラームに対して「管理者宛にメール通知」というアクションを設定すると、条件を満たしたときにアクションが実行されます。なお、メール通知はSNS(Simple Notification Service)というメッセージングサービスと連携して実現します。
EC2インスタンスについては、メール通知だけではなく、インスタンスの再起動・停止・終了・復旧というアクションも用意されています。例えば、必要な処理が完了したらインスタンスを停止・終了することでコストを削減できます。また、復旧アクションを選択すると、ハードウェア異常が発生した際に自動的に新しいハードウェアで復旧します。
Amazon EFS
Amazon EFSはNFS(Network File System)プロトコルをサポートするファイルストレージサービスです。NFSとはネットワーク上にある複数のコンピュータからストレージを共有することができるプロトコルのことです。EFSはNFSに対応したAWSサービスおよびオンプレミス(自社運用)のシステムから利用できます。
EFSは複数インスタンス(複数ユーザー)からの同時アクセスを前提としています。またEBS(およびインスタンスストア)は同一AZ内でのみ利用可能でしたが、EFSでは異なるAZのEC2インスタンスからもアクセスが可能になっています。
Amazon EFS(Elastic File System)はNFS(Network File System)プロトコルをサポートするファイルストレージサービスです。EFSはNFSに対応したAWSサービスおよびオンプレミス(自社運用)のシステムから利用できます。
EFSは異なるAZのEC2インスタンスからもアクセスできます。
ACIDとは、原子性(Atomicity)、一貫性(Consistency)、独立性(Isolation)、耐久性(Durability)を意味する言葉で、更新処理中に中途半端なデータが書き込まれないことや、並行処理がそれぞれ独立して動作する(互いに干渉しない)ことなど、処理の信頼性を保証する性質をいいます。
EFSはデータ更新時の操作結果が即時に他のデータへ反映され、操作直後でも最新のデータが参照できる「強力な整合性」を採用しています。また、複数のAZで冗長化されているので高い耐久性があります。EFSは最大数千のEC2インスタンスから同時アクセス可能な、ACID特性のあるストレージです。
AWS Storage Gateway
AWS Storage Gatewayは、オンプレミスからAWSのストレージサービスへのアクセスを高速かつセキュアに行うことができるサービスです。AWS Storage Gatewayのボリュームゲートウェイには「キャッシュ型」と「保管型」があります。
・キャッシュ型(キャッシュボリューム)
キャッシュストレージをオンプレミス(ローカル)に設置することで、高速アクセスが可能な堅牢性の高いストレージを利用することができます。オンプレミスのキャッシュストレージには頻繁にアクセスするデータのみを保持し、アクセス頻度の低いデータはS3へ保存することで、階層化されたストレージを実現します。
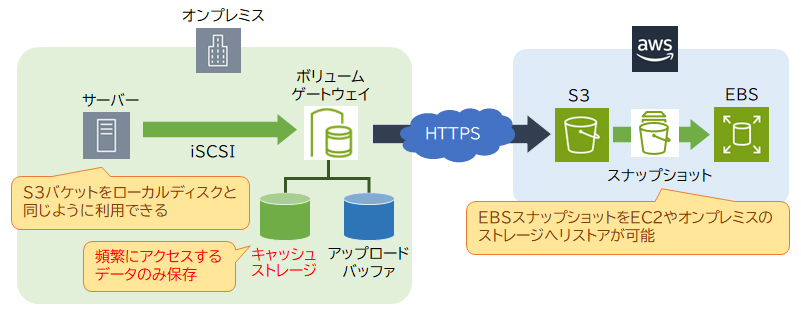
・保管型(ストアドボリューム)
オンプレミスのボリュームストレージに全てのデータを保持します。キャッシュ型とは異なり、全てのデータに対して高速アクセスが可能です。
ボリュームストレージ上のデータは任意のタイミングでS3にスナップショットとして保存されますので、災害対策や定期的なバックアップとして利用できます。
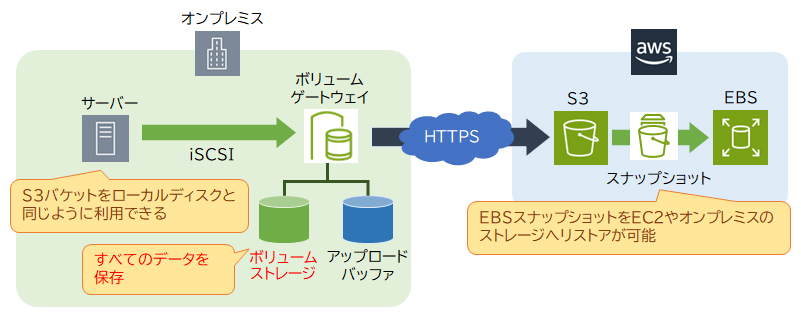
「オンプレミスで利用しているデータとAWSのバックアップデータを統一」する場合、災害復旧のバックアップに適した「保管型(ストアドボリューム)」を設定します。
・AWS Direct Connectでバックアップ環境のVPCとオンプレミスをセキュアに接続する
→オンプレミスからAWSへのフェイルオーバーにDirect Connectは必要ないので、誤りです。
DynamoDB Streams
DynamoDB Streams(ストリーム)とは、テーブルに対して行われた直近の24時間の変更(追加や更新、削除)をログに保存する機能です。ストリームを参照することによって、いつ誰がどのようにテーブルを更新したかがわかります。ログには、アプリケーションがリアルタイムにアクセスできるため、変更内容に応じて処理を組み込むことができます。
なお、DynamoDB Streamsは非同期で動作するため、ストリームを有効にしても元のテーブルのパフォーマンスには影響を与えません。また、DynamoDBはAWS Lambdaと統合されているため、Lambda側のトリガーを使用することで、独自のアプリケーションを用意したり、追加のコードをすることなく連携させることができます。
DAXはDynamoDBのインメモリのキャッシュクラスタです。パフォーマンスの向上などを目的とした機能です。
フェイルオーバー
通常時はオンプレミスでWebアプリケーションを運用し、災害発生時にAWSのバックアップ環境でサービスを継続するには、AWSでフェイルオーバー先のサーバーの構築とバックアップデータの保管が必要です。
まず、フェイルオーバー先のサーバーの構築について考えます。
・ALB配下のEC2インスタンスを停止状態にしておき、障害発生時に起動する
・障害発生時にAWS CloudFormationテンプレートを実行して、ALBとEC2インスタンスを作成する
は、ともにフェイルオーバー後にALB配下のEC2インスタンスでサービスを継続できます。
サーバーが利用可能になるまでの時間を比較すると、前者は作成済みのインスタンスを起動するだけなのに対し、後者はALBとインスタンスの作成時間がかかります。設問の要件に「もっともダウンタイムを少なく」とあるので「ALB配下のEC2インスタンスを停止状態にしておき、障害発生時に起動する」方が適切です。
Amazon EKS
Amazon EKS(Elastic Kubernetes Service)は、AWSが提供するKubernetesのマネージドサービスです。Kubernetesは、オープンソースのコンテナオーケストレーションプラットフォームで、Amazon ECSと同様に、コンテナの実行・管理を行うことができます。
EKSでは、以下の機能を用いることで、実行中のアプリケーションの負荷状況に応じたポッドやノードのスケールアウト/インを実現することができます。
■ Horizontal Pod Autoscaler (HPA)
CPU使用率やメモリ使用量といったメトリクスに基づきポッドの数を自動的に増減させる水平方向のスケーリング機能です。
■ Cluster Autoscaler
ノード(実行環境)の数を自動的に増減させるスケーリング機能です。HPAによりポッドのスケールアウトが発生した時に、追加されるポッドを実行するだけのリソースが既存のノードに不足していると、追加のポッドは起動できず待ち状態(Pending)になります。このような場合に、Cluster Autoscalerは新しいポッドが必要とするリソースに基づいて新しいノードを追加し、逆に不要なノードがあればそれらのノードを終了します。
Amazon Simple Notification Service(SNS)
Amazon Simple Notification Service(SNS)はフルマネージドのメッセージングサービスで、システム間で通知やデータをやり取りするための手段として使われます。このサービスはEメール、SMS、Lambda関数、Amazon SQS、HTTP/HTTPSなど、多様なプロトコルを通じて複数のアプリケーションやユーザーに同時にメッセージを送信することができます。また、SNSはプッシュ型のサービスであるため、登録しているサブスクライバーの状態にかかわらずリアルタイムでメッセージを配信することができます。この即時性は、オンライン注文のステータスが変更された際にすぐに通知を送る必要がある場合に有効です。さらに、SNSはスケーラビリティが非常に高く、新しいサブスクライバーを追加しても容易にシステムを拡張できるため、急速に成長しているビジネスのニーズにも柔軟に対応することが可能です。
[SNSのイメージ図]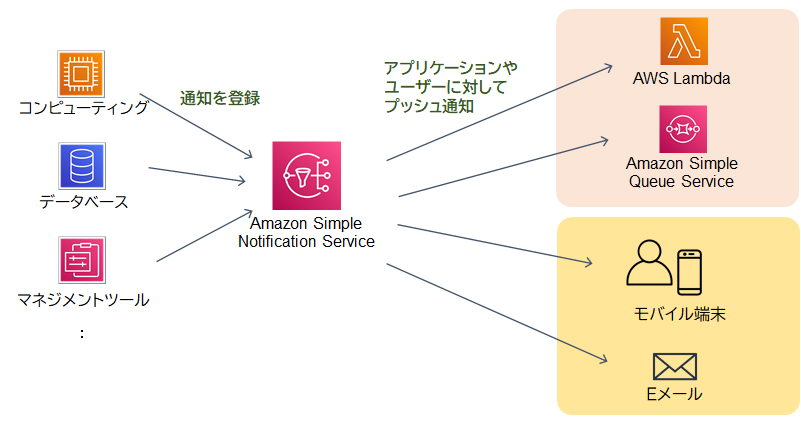
AWS Step Functions
AWS Step Functionsは、複数のAWSサービスをワークフローとして連携させ、処理を自動化するためのフルマネージド型のサーバーレスなサービスです。
専用のGUI(Workflow Studio)を介して、視覚的にワークフローを作成することができます。
また、AWS Lambda、Amazon S3、Amazon ECSなど、多くのサービスをサポートしています。
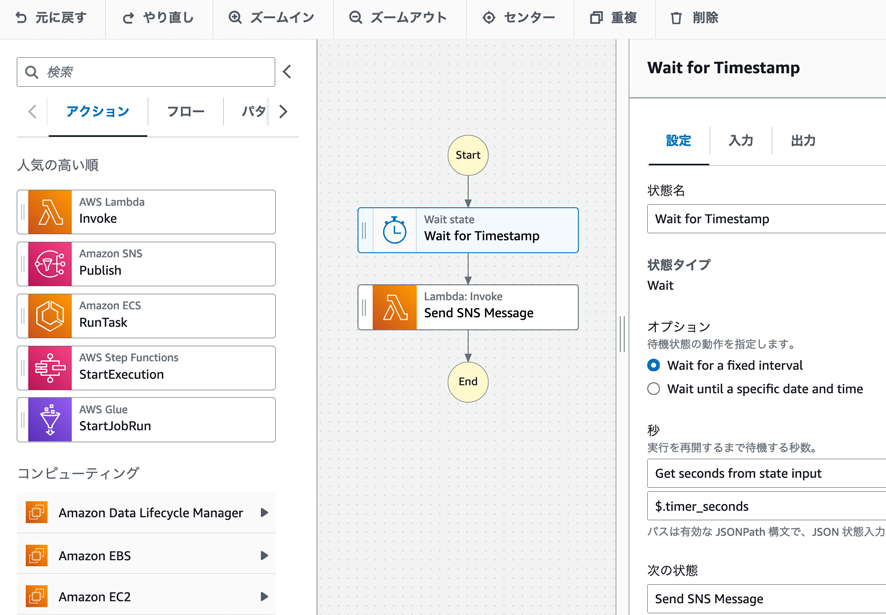
【AWS Step Functionsの主な特徴】
・サーバーレス: インフラの管理やスケーリングの懸念といった運用上のオーバーヘッドを抑えることができる
・専用のGUI: ワークフローを視覚的に作成・管理できる
・多くのサービスをサポート: AWS Lambda、Amazon S3、Amazon ECSなどとの連携が可能
・柔軟なワークフローの定義: 条件分岐や待機時間などをタスクとして組み込むことで、前の処理結果に応じた後続処理を行ったり、人間の手動操作の完了を待つなど、複雑なワークフローを定義できる
・外部サービスとの連携: オンプレミス環境などの外部サービスとの連携も可能
・Amazon API GatewayでREST APIを作成し、API GatewayとEC2の間にNATゲートウェイを設定する
→NATゲートウェイは、プライベートサブネットからインターネットへの通信を可能にする機能です。
・Amazon API GatewayでREST APIを作成し、EC2のセキュリティグループにAPI GatewayのIPアドレスを許可するルールを追加する
→API Gatewayで作成したAPIはVPC外に配置されます。セキュリティグループでIPアドレスの許可ルールを追加しても、APIとプライベートサブネット内のリソースとの間で、インターネットを経由しない接続を確立することはできません。
・Amazon API GatewayでWebSocket APIを作成し、API GAtewayのVPCリンクを作成する
→WebSocket APIではなくREST APIを使用する場合、不適切です。
REST APIを用いてデータを受け付けるサービス
REST APIを用いて約200店舗から販売データをリアルタイムで受け付けるサービスには「Amazon API Gateway」が適切です。API GatewayはAWSサービスと連携するAPIの作成や管理ができる機能です。API Gatewayは高いスループットでリクエストを効率的に処理できるため、リアルタイムで発生するデータを受け付けるサービスに適しています。
ストリーミングデータを変換処理へ配信するサービス
API Gatewayで受け付けたリアルタイムのストリーミングデータをデータ変換処理へ配信するサービスは「Amazon Kinesis」と「Data Firehose」が適切です。「Kinesis Data Streams」は外部から送信されるストリーミングデータを収集します。さらに「Data Firehose」はKinesis Data Streamsからデータを受け取ったあとデータ変換処理へ配信し、処理結果をS3バケットに保存します。
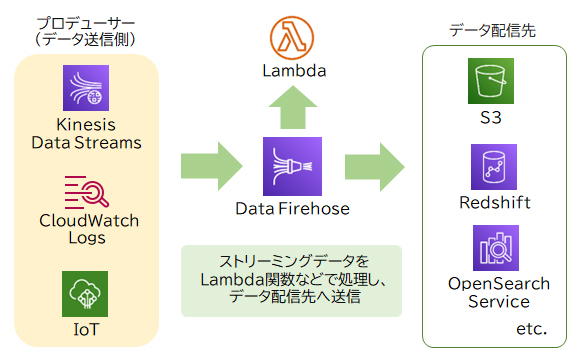
データ変換処理を実施するサービス
データの変換処理をするサービスは「AWS Lambda」が適切です。Lambdaはサーバーレスでプログラムのコードを実行できるサービスです。
API Gateway、Kinesis、Lambdaはすべてサーバーレスなサービスなので、サーバー管理の運用コストを最小限に抑えられます。
AWS Direct Connect
AWS Direct Connect(DX)はオンプレミスなどのユーザー環境からAWSへ、専用回線を使ってセキュアに接続するサービスです。インターネット回線ではなく専用回線を敷設して使用するので、安定した高速なネットワークで接続できます。AWSユーザーはDirect Connectロケーション内にルーターを設置し、オンプレミスから専用線を引き込む必要があります。工事費用と時間をかけてでも、安定した通信と強固なセキュリティ環境を求めるケースに適しています。
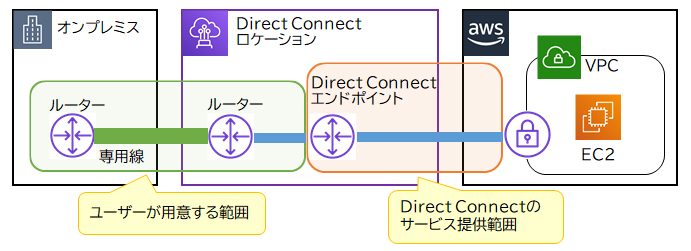
AWS Site-to-Site VPN(サイト間VPN)は、カスタマーゲートウェイ(オンプレミスのルーター)とVPCの仮想プライベートゲートウェイ(VGW:Virtual Private Gateway)を、インターネットVPNで接続するサービスです。AWS Site-to-Site VPNではインターネット回線を利用するので、専用回線を敷設するDirect Connectよりも安価に、かつ短い期間で接続を開始できます。
「できる限り低遅延な通信で、インターネット回線に影響を及ぼさない方法を採用したい」一方、高可用性の実現は「通信経路を複数確保したいが、コスト削減も必要なので障害時における通信のパフォーマンス低下は許容する」という要件を満たすには、通常時はAWS Direct Connectの安定した高速なネットワークを利用し、Direct Connectが障害で利用できない時はAWS Site-to-Site VPNで通信手段を確保するのが適切です。
RDS
・AWS Data Pipelineを使用して、DBスナップショットからAuroraデータベースクラスタにデータを移動する
→AWS Data Pipelineは、データの移動や変換を自動化するサービスですが、DBスナップショットを直接扱うものではありません。
・DBスナップショットをAmazon EBSボリュームに変換し、変換したボリュームからAuroraデータベースクラスタにデータを移動する
→DBスナップショットをEBSボリュームに変換することはできません。
・Amazon DMS (Database Migration Service)を使用して、DBスナップショットからAuroraデータベースクラスタに直接データを移行する
→Amazon DMSはデータベースの移行をサポートするサービスですが、DBスナップショットからの移行は行えません。
AWS Backup
AWS Backupとは、ストレージやデータベース等のバックアップを一元管理するフルマネージドのサービスです。
EC2インスタンスやEBSボリューム、S3バケット、RDSなどを対象に、柔軟なバックアッププランを作成できます。例えばバックアップの頻度や、一定期間を経過したバックアップはコールドストレージ※へ保存する、別のリージョンへ保存するなどの運用ができます。
※コールドストレージ…あまり利用されないデータを保存するストレージ。容量が大きく、安価で利用できる。
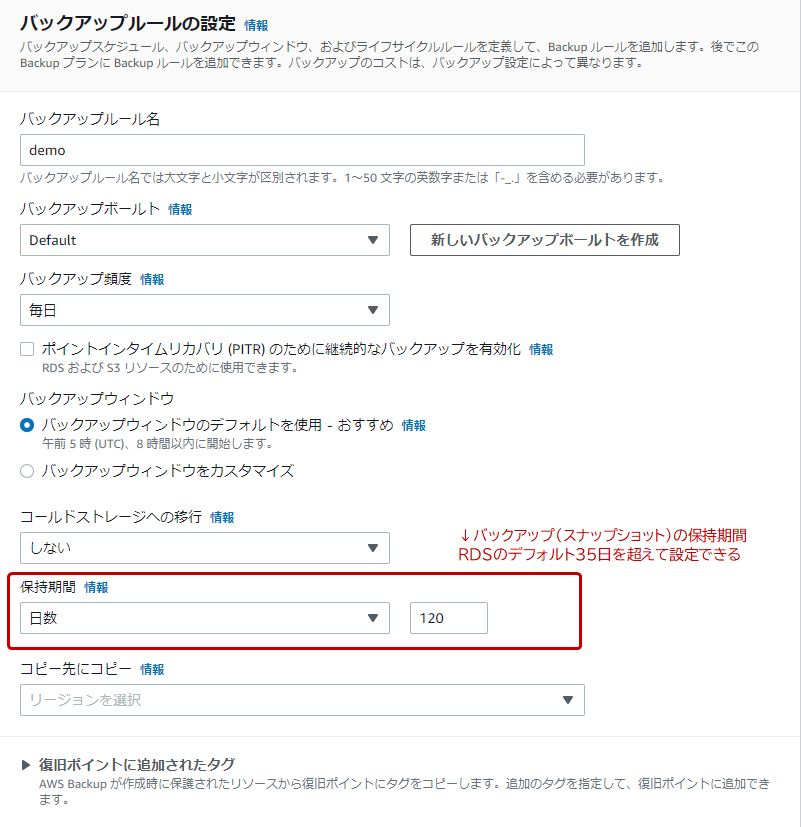
RDSにおける自動バックアップの保持期間は最大で35日です。35日を超えてスナップショットを保持したい場合は以下の方法があります。
– AWS Backupでバックアッププランを作成する
– 手動でスナップショットを取得する
手動で取得したスナップショットには保持期間の上限がありません。
– 自動バックアップで取得したスナップショットをS3バケットへ手動でコピー(エクスポート)する
S3バケットへのコピーは、RDSのスナップショット管理画面やAWS CLIなどから行います。
以下はAWS Backupの設定画面です。
Auto Scaling
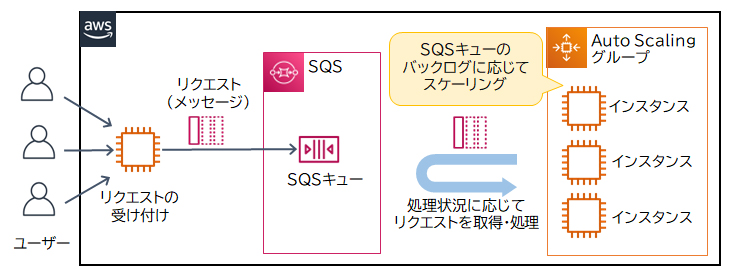
Auto ScalingはAWSリソースを負荷状況や設定したスケジュールに従って、自動的にスケーリングする機能です。
スケーリングの発生条件のうち「動的スケーリング」は、CPUやネットワークなどのパフォーマンスの負荷状況に応じて、自動的にスケールアウト(リソースの増加)/スケールイン(リソースの削減)を実施します。
リクエストが急激に増加した場合、SQSとCloudWatch、Auto Scalingを連携することでインスタンスを自動的にスケーリングできます。リクエストの増加によりSQSキュー内にある処理待ちのメッセージ数(バックログ)がしきい値を超えたときにCloudWatchがアラートを上げ、Auto Scalingがインスタンスを増やします。キューにメッセージがなくなり次第スケールインすることで、コストを抑えた運用が実現できます。
NLB
NLBはレイヤー4(トランスポート層)で負荷分散を行い、TCP、UDP、TLSをサポートしています。NLBのターゲットにオンプレミスのサーバーのIPアドレスを指定することで、クライアントからNLBに接続し、AWS VPNを経由してオンプレミス上のサーバーに負荷分散できます。また、NLBはElastic IPアドレスを割り当てられるので、ユーザーはNLBの固定IPアドレスへアクセスします。
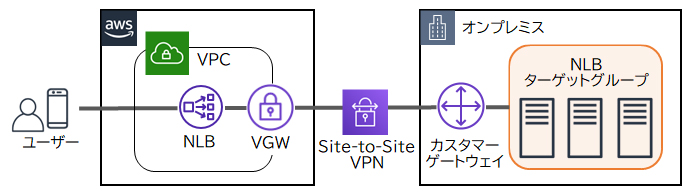
NLBはターゲットグループ内の各ターゲットが正常に動作しているかを定期的に確認します。ターゲットから正常に応答が返ってくればNLBからリクエストをターゲットへ転送し、異常があれば転送を停止します。複数台のサーバーをターゲットグループに登録することにより、1台のサーバーに障害が発生しても、他の正常なサーバーへリクエストが転送されるので、システムの可用性が高くなります。
[ALB/NLB/CLBの比較表]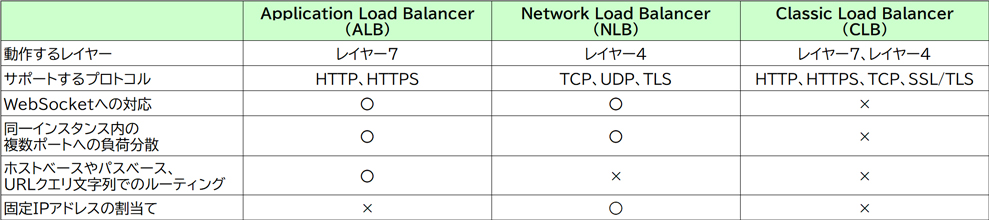
Global Acceleratorは、ユーザーからAWSリソースまでのアクセス経路をAWSネットワークを利用して最適化するサービスです。エンドポイントにオンプレミスのサーバーを登録することはできません。
Amazon ECS
大きな機能を一つに総括したシステムをモノリシックなシステムといいます。モノリシックとは反対に、最小限の機能を持つ独立したサービスのことをマイクロサービスといいます。
マイクロサービスの主なメリットは、ある機能に障害が発生したりアップデートした場合に他の機能への影響を最小限にできること、機能を別のサービスに流用することが容易になるので開発コストの削減に繋がることなどが挙げられます。
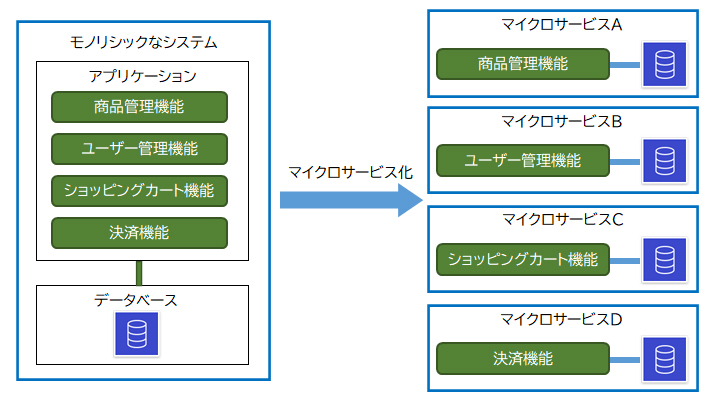
Amazon ECS(Elastic Container Service)はコンテナを実行、管理するサービスです。「コンテナ」とはアプリケーションと実行環境をパッケージ化する仮想化技術の一種のことです。
コンテナはマイクロサービスの実現に適しています。ひとつのサービスをひとつのコンテナで実行することで効率的にマイクロサービスを構築できます。
Amazon SQSはフルマネージドのメッセージキューイングサービスです。「メッセージキューイング」とは個々のサービスやシステムをメッセージを使用して連携する仕組みのことで、サービス同士の橋渡しを担います。Amazon SQSはプル型なので、受信側の都合の良いタイミングでSQSへポーリング(問い合わせ)を行って、メッセージを受け取ります。
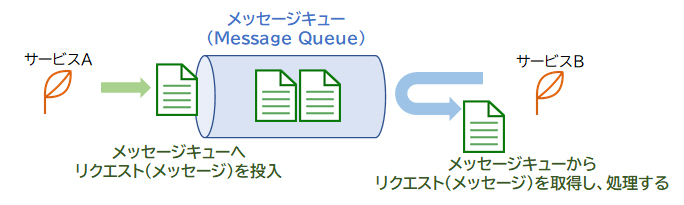
サービスAはクライアントからのリクエストを受け、キュー(queue)と呼ばれる領域にリクエスト(メッセージ)を投入します。サービスBはキューからメッセージを取得し、処理します。
メッセージキューを利用すると、お互いのサービスがそれぞれの状況に関係なく(非同期で)処理を進行できるため、サービス間の結合度が低くなります。このように、システムを構成するサービスやコンポーネント間の結合度や依存度を低くし、独立性を高めることを「疎結合」または「デカップリング」といいます。
サービス間の結合度を低くすると以下のようなメリットがあります。
・関連するサービスの負荷や処理状況に引きずられずに自身の処理を進行できる
・関連するサービスで障害が発生した場合やアップデートなどの際に影響を受けずに済む
SQSはこのようにサービス同士を橋渡しする役割を持つAWSサービスです。
設問のケースに当てはめると、モノリシックな多階層構成のアプリケーションをECSで動作する2つのコンテナでマイクロサービス化します。そして、1つ目のデータ統合用のプログラムより、2つ目のデータ解析用のプログラムの方が処理に何倍も時間がかかるので、各プログラムが非同期でプログラムを実行できるようにSQSでデカップリングします。
・プログラムをAmazon ECSで動作する2つのコンテナに再設計する。データ統合用プログラムは処理が完了した後、SNSへイベントを通知する。データ解析用プログラムはSNSトピックをサブスクライブして処理を実行する
SNSはプッシュ型のメッセージングサービスです。SNSの通知はリアルタイム性の高い処理に向いています。
デカップリングは実現できますが、非同期でリクエストをやりとりするにはSQSの方が適しています。
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント