
人工知能
予備知識
『人工知能は人間を超えるか ディープラーニングの先にあるもの』松尾豊東京大学准教授
鈴木大慈「機械学習の数学」ー高校生のための東京大学オープンキャンパス2017 模擬講義
人工知能の定義
人工知能とは 「人工知能」とは、推論、認識、判断など、人間と同じ知的な処理能力を持つ機械(情報処理システム)。
ジョン・マッカーシー(John McCarthy)
「人工知能(Artificial Intelligence)」という言葉は、1956年にアメリカで開催されたダートマス会議において、著名な人工知能研究者であるジョン・マッカーシーが初めて使った言葉。
ダートマス会議
「人工知能(Artificial Intelligence)」という言葉が初めて使われた会議。
アーサー・サミュエル(Arthur Lee Samuel)
「機械学習」の定義は、アーサー・サミュエルの「明示的にプログラムしなくても学習する能力をコンピューターに与える研究分野」が有名。
深層学習とは 深層学習
ディープニューラルネットワークを用いて学習を行うための研究分野のこと。
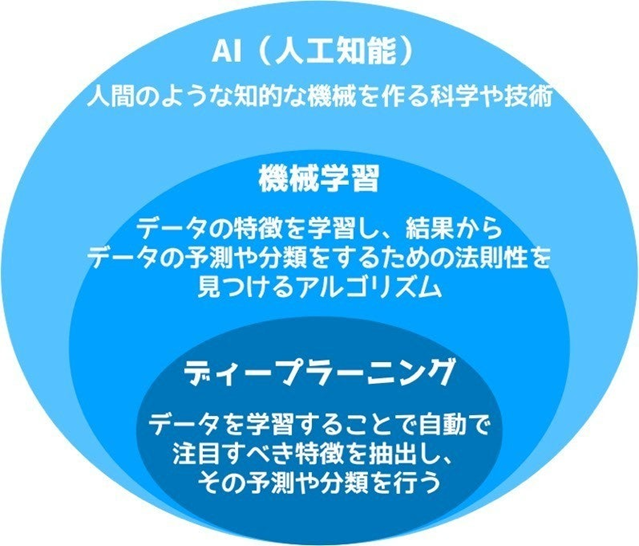
AI、機械学習、ディープラーニングの関係性
人口知能の歴史
第1次AIブームとは 第1次AIブーム「推論・探索の時代」
第一次AIブームとは
1950年代後半〜1960年代、探索と推論により問題を解く人工知能が台頭。但し、複雑に絡みあった現実の問題を解くには至らなかった。
検索と推論
あるルールとゴールが決められた枠組みの中で、なるべく早くゴールにたどり着く選択肢を選び続けること。 トイプロブレムとは トイプロブレム
検索と推論で解ける問題はゲームの有利な手などトイプロブレムに限られる(トイプロブレムしか解けない)ことが第1次AIブームで明らかになり、ブームは終焉を迎えた。
ヒューリスティックとは ヒューリスティックな知識
ヒューリスティックな知識とは 「経験的な」知識という意味。ボードゲームの手などを効率的に探索するための「経験的な」知識。
第2次AIブームとは 第2次AIブーム「知識の時代」
第二次AIブームとは
1980年代には、エキスパートシステムにより問題を解く人工知能が台頭。
しかし、専門家の知識は膨大かつ定式化は難しく、複雑な問題が解けるようにはならなかった。そして、第2次AIブームも終焉。
エキスパートシステムとは エキスパートシステム
専門家の知識をそのまま人工知能に移植することにより様々な問題を解決するというアイディア。
知識ベースと推論エンジンからなる。
知識ベースとは 知識ベース
「もし・・・ならば」という規則による知識の集まり。
推論エンジンとは 推論エンジン
知識ベースを用いて推論を行うプログラムのこと。
オントロジーとは オントロジー
知識を体系化する方法論。is-aとpart-of。
Cycプロジェクトとは Cyc(サイク)プロジェクト
サイクプロジェクトとは 全ての一般常識をコンピューターに取り込もうというプロジェクト。これは、ヘビーウェイトオントロジー(哲学的な考察が必要)の一つ。
2001年からOpenCycとして一部が一般公開されている。
ヘビーウェイトオントロジーとは ヘビーウェイトオントロジーとライトウェイトオントロジー
ライトウェイトオントロジーとは Cycプロジェクトのように哲学的な考察が必要なのがヘビーウェイトオントロジー。
正確でなかったとしても、コンピューターで概念間の関係性を見つけようという取り組みがライトウェイトオントロジーとなる(ウェブマイニングや、データマイニングなど)。
第3次AIブームとは 第3次AIブーム「機械学習と特徴表現学習の時代」
第三次AIブームとは
2000年代以降の第3次AIブーム。発端はILSVRCという画像認識・一般物体認識の精度を競うコンペディション。
2012年のISLVRC2012にて、ジェフリー・ヒントン率いるカナダ・トロント大学のSuperVisionチームがディープラーニングを用いて圧倒的な成績で優勝(前年まではサポートベクターマシンが優勝)。
これをきっかけとして、ディープラーニングが一気に脚光を浴びることとなり、現在の第3次AIブームにつながる。
ジェフリー・ヒントン(Geoffrey Everest Hinton)
ディープラーニングを用いてILSVRCで2012年に優勝。 ILSVRCとは ILSVRC
ImageNetLargeScaleVisualRocognitionComoetition。ImageNetというデータセットを使用する。
画像認識・一般物体認識コンペティション。
補足シート:ILSVRC
AlexNetとは AlexNet
ILSVRC2012でジェフリー・ヒントンが用いた8層のディープニューラルネットワークで、畳み込みニューラルネットワーク(CNN)の一種。
特徴表現学習とは 特徴表現学習
機械学習自身に特徴量を発見させるアプローチのこと。
チューリングテストとは チューリングテスト
ある機械が人工知能かどうかを判定するためのテスト。人間の審査員に、相手がAIか否かを当ててもらうもの。
画面とキーボードを使って会話を行い、その相手がコンピューターであるかを見分ける。
アラン・チューリング
1950年の論文でチューリングテストを発表した。
ELIZA(イライザ)
1966年に発表された自然言語処理プログラム。精神科セラピストの役割を演じリルプログラムで、かなりの判定者を惑わせた。
PARRY(パリー)
イライザの後に開発され、これも多くの判定者を誤らせた。
RFC439
イライザとパリーが会話した最初の記録はRFC439として残されている。
フレーム問題
人工知能が何を考慮すべきで何を考慮すべきでないかを判断するのに、有限の計算資源しか持たないAIは膨大な時間がかかってしまうという問題。 強いAIとは 強いAI(汎用AI)と弱いAI(特化型AI)
弱いAIとは 人間のようにあらゆる問題に適切に対処できるAIを強いAI、
知能を持たず特手の分野の問題のみを解決することが可能なAIを弱いAIといいます。
チェスに特化したディープ・ブルーや、自然言語に特化したSiri等が弱いAIに該当する。
ダニエル・デネット
「今しようとしていることに関係あることがらだけを選び出すことが、実は非常に難しい」。
人間 VS AI
Watson(IBM)
2011年 クイズ王を打ち破る。 AlphaGoとは AlphaGo(Google DeepMind)
AlphaGoとは 2015年人間のプロ囲碁棋士をハンディキャップなしで破る。
ディープ・ブルーとは ディープ・ブルー(IBM)
DeepBlueとは 2015年チェスAI 力任せの探索で1997年にはチェスの世界チャンピオンを破る。
Ponanza
2015年将棋AI プロ棋士を破る。 シンギュラリティとは シンギュラリティ
「人工知能が人間を超えて文明の主役に取って代わる」時点のこと。シンギュラリティ(技術的特異点)と呼ばれている。レイ・カーツワイルが提唱。
レイ・カーツワイル
「シンギュラリティは2045年に到達する」。
ヒューゴ・デ・ガリス
「シンギュラリティは21世紀後半に来る」。
「そのとき、人工知能は人間の知能の1兆の1兆倍になる」。
イーロン・マスク
シンギュラリティ到来に危機感を持ち、非営利の研究組織OpenAIを設立。テスラやスペースXの人。
オレン・エツィオー二
「100万年後にシンギュラリティが来るかもしれないけど、そんな終末思想は馬鹿げてる」といった趣旨のことを言った人。
スティーブン・ホーキング
「AIの完成は人類の終焉を意味するかもしれない」=「人工知能の進化は人類の終焉を意味する」。 シンボルグラウンディング問題とは シンボルグラウンディング問題(記号接地問題) 検索用・・・シンボルグランディング
シンボルグラウンディングとは
記号(シンボル)とその対象がいかにして結び付くかという問題。
フレーム問題。コンピュータは「記号(文字)」の意味が分かっていないので、記号が意味するものと結び付けることができない。
身体性
知能が成立するためには身体が不可欠であるという考え方。「外界と相互作用できる身体がないと、概念はとらえきれない」と考える。
AI効果
人工知能の原理が分かってしまうと、「それはAIではない」と思われてしまう人間心理。
LAWS
自律型致死兵器(LAWS)とは、AIなどにより完全に自律して、かつ強力な殺傷能力を持つ兵器のこと。まだ現段階では存在していないが、議論は続いている。
アシロマAI原則
「AIによる軍拡競争は避けるべきである」。
人工知能の分類、レベル レベルとは
レベル1とは
レベル2とは
レベル3とは
レベル4とは
画像参照:人工知能のおおまかな分類 – 【AI・機械学習用語集】 機械学習とは 機械学習
機械学習の3種類
教師あり学習
機械学習 教師なし学習
教科学習 教師あり学習とは 教師あり機械学習
教師データを用いてモデルが学習を行うことにより、未知のサンプルの正解ラベルを予測する一連の学習方法。
やることは「分類」と「回帰」の2つ。
教師あり学習では、未知のサンプルに対して、精度の高い回帰や分類が行われているかをあらわす汎化性能を確認する必要がある。
例えば分類問題におけるモデルの汎化性能を考える場合、適切な性能指標を見出すためには混合行列が利用される。 回帰とは 回帰(regression)、回帰問題
回帰問題とは 連続する入力値に対する次の値を予測すること。
出力値の予測(近似)。たとえば家賃、年収、気温の予想。つまり数値的な予測。
代表的な手法:線形回帰。線形回帰には単回帰分析と重回帰分析がある。深層学習でも回帰を行うことがある。
分類とは 分類(classification)、分類問題
分類問題とは あらかじめ設定したクラスにデータを割り振る。たとえば画像で犬、猫にわける、○○かそうでないかを予測する。
0か1かラベルを予測する(二項分類)。また、3つ以上分類(多項分類)することも可能。
代表的な手法:サポートベクターマシン、決定木、ランダムフォレスト、ロジスティック回帰、kNN法などの手法がある。深層学習でも分類を行うことができる。
クラス分類ともいう。
分類問題と回帰問題を解く教師あり学習のアルゴリズムの一つとして決定木がある。
回帰と分類の違い 回帰と分類の違い
分類と回帰の違い 目的変数が異なる。回帰では連続値。分類では離散値となる。
予測する値も回帰では連続値となるが、分類では離散値となる。
過学習とは 過学習(オーバーフィッティング)
学習に用いたデータに対しては高い精度で予測できるのに、学習に用いていないデータでは精度が上がらない事象のこと。機械学習における最大の問題と呼ばれている。
ホールドアウト法とは ホールドアウト法
データを訓練データ(学習データ)とテストデータ(検証用のデータ)に分割してモデル評価を行う方法です。 過学習を防ぎます。
1.訓練データ ←学習用の教師データ
教師あり学習のデータ
2.テストデータ ←これをちょっとどけておいて、あとで学習効果を想定するのに使う 一つ抜き交差検証とは 一つ抜き交差検証(leave-one-out cross-validation / LOOCV)
leave-one-outとは 手元のデータのうち,一つだけをテストデータとして他の全てを学習データとする方法。
LOOCVとは ほぼ全てのデータを学習データとして使うことができるので,手元にあるデータを無駄なく使用することができる。
学習データの数だけモデルを構築するため、非常にコストがかかることが欠点。
情報量基準とは 情報量基準
情報量規準とは一言でいうとモデルを選択する際に使われる,モデルの良し悪しの指標のこと。
情報量基準にはAICとBICがある。
AICとは AIC(赤池情報量基準)
赤池情報量基準とは モデルの当てはまり度合いを表す指標で、AICの値が小さいほど「よい」モデルとみなせる指標。
説明変数として利用する変数ができるだけ少なくするようなモデルを高くする指標。
BICとは BIC(ベイズ情報量基準)
ベイズ情報量基準とは エビデンス(周辺尤度)のラプラス近似。
この値が小さいモデルを良いモデルとして選ぶ。
k-NNとは k-NN (k近傍法) ※近傍法:きんぼうほう
k近傍法とは データのクラスタリング (グループ分け) をする際に、「予測データに近いデータ k 個の多数決によってクラスを推測」するアルゴリズムです。
距離が近いもの同士を同じクラスだと捉えることが一般。
【入門】k-NN (k近傍法) とは?わかりやすく解説 | ほげほげテクノロジー 教師なし学習とは 教師なし機械学習
教師データを使わずに、データの本質的な構造を浮かび上がらせる手法。代表的な手法はクラスタリングと次元削減。
手法・・・k-means(=k平均法)、主成分分析(PCA)、独立成分分析、自己符号化器
クラスタリング 例:k-means
教師なし 異常検知 異常検知のアルゴリズム(SVM)は、セキュリティシステムなどに使用されている
次元削減 クラスタリングとは クラスタリング
与えられた「データ群をいくつかのあつまり(クラスタ)に分けること」で、データの本質的な構造を浮かび上がらせる(グループに分ける)手法。
クラス分類(20行くらい上の青字)とは異なるものなので、注意。
方法として、クラスタの中心点となる点をランダムに生成する。
次に各データを中心点からの距離が最も近いクラスタに属するものとして、重心を計算し、クラスタの中心を重心にずらす。
具体的な手法:k-means法
クラスタリングとクラス分類の違い
エンジニアが「事前にグループを設定するかどうか」の違いがある。
クラスタリング(教師なし)
事前にグループ設定自体は行わない。グループ自体の抽出をする。
※しつこいかもだが
分類(=クラス分類) ・・・ あらかじめ設定したクラスにデータを振り分ける
回帰 ・・・ 数値(あるいは数値の組)を予測する
クラスタリング ・・・ データの類似度をもとにいくつかのグループに分ける 強化学習とは 強化学習
目的・・・収益(報酬の和)を最大化する方策を獲得すること。エージェントが行動を選択すると状態が変化する。それを繰り返し最良の方策を獲得する
エージェント=ある環境で動くプレイヤー
収益=エージェントが行動することで得られる評価値
行動=エージェントがとる行動
状態=エージェントが置かれている環境
方策=ある状態のとき、どの行動をとるべきかを示す関数
価値関数=将来的に得られる収益の期待値を表す関数
マルチエージェントシミュレーションとは マルチエージェントシミュレーション
マルチエージェントシステムを用いた社会シミュレーションのこと。
環境や条件を変えながら社会変化の背景にあるメカニズムを知ることができる。
マルチエージェントシステムとは マルチエージェントシステム
自ら状況を認識し、それに基づいて判断・行動する主体(=エージェント)が、複数存在するシステムのこと。
例:交通や群衆の振る舞いなど
DQNとは Deep-Q-Network (DQN)
価値関数を計算するディープニューラルネットワーク。ディープマインド社が作った。これを使うものは深層強化学習と呼ぶ。
マルチエージェントに関して、学習過程の不安定さがみられるため、これに対応するために逆強化学習やディープラーニングの技術を応用したDQNが適用され始めている。
・正解データ付きの訓練データを用意する必要がない
・学習には時間がかかる
・状態遷移を考慮することができる
・汎用性が低い
その他の機械学習 半教師学習とは 半教師学習という、教師あり学習におけるラベル付けのコストを低減するために用いられる手法もある。
機械学習のプロセス
基礎集計 → 前処理 → 特徴量エンジニアリング → 計算 → 性能評価
基礎集計
データの動向を事前に把握する。
各種代表値(平均や分散)を見たり、散布図行列をプロットしたり、相関行列を表示して傾向を見たりする。 前処理とは 前処理
データをモデルに正しく入力できる形にする。
正規化とは 正規化 補足シート:○○化
最大値で割る計算を行い、すべてのデータを0~1の間にすること。
標準化とは 標準化
データに対しの平均を0、標準偏差が1になるように計算すること。
名寄せとは 名寄せ
表記の揺れなどを統一すること。
引っかけ問題で出題されやすい「正則化」は過学習を抑制するための手法であって、前処理の用語ではありません。
画像データの前処理 グレースケール化とは グレースケール化 … カラー画像を白黒画像に変換して計算量を削減する
平滑化とは 平滑化 … 細かいノイズの影響を除去する
ヒストグラム平均とは ヒストグラム平均 … 画素ごとの明るさをスケーリングする
局所コントラスト正規化とは 局所コントラスト正規化 … 減算正規化と除算正規化の処理を行う
特徴量エンジニアリング
モデルが認識しやすい特徴をデータから作ること。
文字列の日付データを数値列に変換したり、多項式特徴量を生成したりすること。
カテゴリカル変数(何かの種類を表す変)をカテゴリカル変数であるとわかるようにすることも、特徴量エンジニアリング。 特徴量とは 特徴量
扱っているデータをよく表す特徴を数値で示したもの。
one-hot-encodingとは one-hot-encoding
onehotencodingとは たった一つの成分だけが1、残りの成分が0という形の特徴量(ベクトル)に変換すること。
性能評価
1.ホールドアウト法 この上に説明あり ホールドアウト法とは で検索
性能評価
2.交差検証 交差検証とは 交差検証法(クロスバリデーション法) = k分割交差検証という書き方になっていることもありますが同じもの
交差検証法とは 教師データをいくつかに分割し、テストデータに用いるブロックを順に移動しながらホールドアウト法による検証を行い、その精度を平均しててモデルの制度を測る(テストデータを順番に移動)。
計算量は大きくなるが、データが少なくてもホールドアウト法と比較して信頼できる精度が得られる。
正則化とは 正則化
パラメータのノルムが大きくなりすぎないようにして、過学習を抑制する。
学習に用いる式に項を追加することによって、とりうる重みの範囲を制限して、過度に重みが訓練データに対してのみ調整されてしまうことを防ぐ手法。
モデルが実際に運用された時の性能を向上させることが可能となる。
ただし、やりすぎると、アンダーフィッティングを起こしてしまう。
L1 例 LASSO ・・・ 不要と判断された特徴量が自動的に消去される性質を持つ
L1正則化を使用するとスパースになる
正則化 L2 Ridge正則化 ・・・ 特徴量の選択は行わないが、パラメータが全体として大きくなりすぎないように制御を行う(=ノルムを小さく抑える)
パラメータのノルムにペナルティを課す Ridge正則化を使用してもスパースにはならない
weight decay
Elastic Net L1正則化とは L1正則化
一部のパラメーターをゼロにすることで、特徴選択をおこなうことができる。これを線形回帰に適用した手法をラッソ回帰(Lasso回帰)と呼ぶ。
ラッソ回帰とは ラッソ回帰(Lasso回帰)
Lasso回帰とは 重回帰分析にL1正則化を用いた手法。
自動的に特徴量選択を行い、重要でないと判断された特徴量は自動的にモデルから消えるようになっている。
不必要なデータの重みを0にし、次元圧縮が可能となる。
スパース正則化とは スパース正則化
L1正則化は、スパース正則化の一種である。
L2正則化とは L2正則化
パラメータのノルムにペナルティを課す。
パラメーターの大きさに応じてゼロに近づけることで汎化された滑らかなモデルを得ることができる。これを線形回帰に適用した手法をリッジ回帰と呼ぶ。
そして、ラッソ回帰とリッジ回帰の両方を組み合わせた手法をElastic Netと呼ぶ。
リッジ回帰とは リッジ回帰(Ridge回帰)
Ridge回帰とは 重回帰分析にL2正則化を用いた正則化手法。
リッジ回帰には特徴量の削減効果はない。
ElasticNetとは Elastic Net
ラッソ回帰とリッジ回帰の両方を組み合わせた手法をElastic Netと呼ぶ。
バッチ正規化とは バッチ正規化
一部の層の出力を正規化し、出力値の分布の偏りを抑制する。
勾配消失が起こりにくくなり、学習が高速化する。
初期値への依存が少ない。
外れ値が少なくなるため、過学習が起こりにくい。
内部共変量シフトという学習がうまくいかなくなる原因を解決するための手法。
内部共変量シフトとは 内部共変量シフトとは
大規模なニューラルネットワークの学習が困難となる原因の一つ。
ある層の入力がそれより下層の学習が進むにつれて変化すること。
(入力の分布が学習途中で大きく変わってくる問題)。
再現率とは 再現率 (Recall)
Recallとは 正解データの内、AIが正例だと予測をしたもの割合を表す評価指標。
適合率とは 適合率(Precision)
Precisionとは 真と予測したもののうち、実際に真であるものの割合。
機械学習の具体的な手法 線形回帰とは 線形回帰
回帰の代表的な手法。 回帰:教師あり学習
線形回帰を一言で説明すると、「説明変数の1次関数で目的変数を予測する」。
単回帰分析とは 単回帰分析
1つの説明変数(例:その日の気温)から目的変数(例:その日の飲み物の売上)を予測する。
重回帰分析とは 重回帰分析
複数の説明変数から目的変数を予測する。
重回帰分析をやる際には、多重共線性に注意しなくてはならない。
重回帰分析において、学習させて作成したモデルがどれくらい制度の良いものなのかを評価するには、決定係数を用いるものとRMSEを用いるものがある。
多重共線性とは 多重共線性
マルチコ(multicollinearity)とも呼ばれる。
相関係数が高い(1か-1に近い)特徴量の組みを同時に説明変数に選ぶと、予測が上手くいかなくなる事象のこと。
相関係数とは、特徴量同士の相関の正負と強さを表す指標。
決定係数とは 決定係数
重回帰分析の結果を読み取る指標のひとつ。
0から1までの値をとります。1に近いほど、回帰式が実際のデータに当てはまっていることを表しています。
RMSEとは RMSE(Root Mean Square Error 二乗平均平方根誤差)
RMSEは平均二乗誤差の平方根のこと(誤差の二乗の平均の平方根)。予想した数値と実際の数値がどれだけずれているかを測る指標。
ロジスティック回帰とは ロジスティック回帰
ロジスティック回帰は2値分類問題を解くことができる。
線形回帰を分類問題に応用するためのアルゴリズムで、次の流れをとる。
対数オッズと呼ばれる値を重回帰分析により予測する。
対数オッズにロジット変換を施すことで、クラスに属する確率の予測値を求める。
また、ロジット変換を行うことにより、出力値が0から1の間の値に正規化され確立としての解釈が可能。
ロジスティック回帰分析における偏回帰係数の推定には最尤法(さいゆうほう)を用いる。
応用例:異常検知、病気の可能性、気象観測 など。
最尤法とは 最尤法(さいゆうほう)
与えられた観測値から尤度を最大にするようなパラメーターを推定する方法のこと。
最尤法によって推定された値を最尤推定値といいます。
簡単に言うと、「いろいろなパラメーターの値を使ってある事象が起こる確率を計算してみて、一番確率が高くなったときにその値をパラメーターの推定値にする」という方法です。
決定木の例kNN法とは kNN法
分類の一手法。未知のデータの近くからk個のデータを調べて多数決によって所属クラスを決定するアルゴリズム。欠点としては、クラスのサンプル数の偏りに弱い。
ちなみに、kの値はエンジニアが事前に設定しておくパラメーターであり、こういったパラメーターはハイパーパラメーター(2,30行下に用語あり)と呼ばれる。
決定木とは 決定木
条件分岐を繰り返すことにより分類や回帰を行うためのアルゴリズム。情報利得の最大化(=不純度がもっとも減少ともいう)を実現するように決定する。
データのスケールを事前にそろえておく必要がなく(前処理が少なく済む)、分析の説明が容易というメリットがある。
剪定とは 剪定(せんてい)
枝刈りや木を整えるという意味があり、決定木に対して汎化性能を損なわないように条件分岐回数の初期値を設定すること。
ランダムフォレストとは ランダムフォレスト
決定木を用いる手法。特徴量をランダムに選び出して、ランダムに複数の決定木を作り出し、それぞれの決定木の結果を用いて多数決を採る手法。
ランダムフォレストは、大雑把にいうとバギング+決定木のことをさし、決定木の良さを引き継ぎながら、過学習を起こしやすいという弱点をある程度解消したアルゴリズム。 ランダムフォレストの例
アンサンブル学習とは アンサンブル学習 アンサンブル=「一緒に」「同時に」
複数のモデルを融合させ、分類は多数決、回帰は一般に平均を結果として採用する手法。
バギング 各モデルを並列に実行
アンサンブル学習 一概にどちらのほうが性能が高いとは言い切れない
ブースティング 各モデルを逐次的に実行 バギングとは バギング
アンサンブル学習の一つ。
複数のモデルを別々に学習させ、各モデルの平均や多数決によって最終的な判断をする手法。
ブースティングとは ブースティング
アンサンブル学習の一つ。
バギングと同様に一部のデータを繰り返し抽出して複数のモデルを学習する手法。
バギングとの違いが、複数のモデルを一気に並列作成する(バギング)か、逐次的に作成する(ブースティング)か、というところ。
ブースティングもモデル部分には決定木が用いられており、AbaBoostや勾配ブースティング木やXgBoostなんかが有名。
ランダムフォレストと勾配ブースティングを比べた時、並列的なランダムフォレストの方が計算は速いが、精度は勾配ブースティングの方が良いといわれている。
マルチタスク学習とは マルチタスク学習
一つの画像でいろいろなタスクを単一のモデルで学習し汎化性を上げようとするもの。
ブートストラップとは ブートストラップ(=ブーストストラップサンプリング)
全てのデータをつかうのではなく、それぞれの決定木に対して一部のデータを取り出して学習させる。
学習データからランダムにサンプリングする手法や、サンプリングした部分集合を指す。
次元削減とは 次元削減
主成分分析(PCA)とは 多次元からなる情報を、その意味を保ったまま、それより少ない次元の情報に落とし込むこと。
用途としては、「データ容量の節約」、「特徴量の作成」、「データの可視化」である。
主成分分析とは 主成分分析(PCA)
PCAとは 主成分分析とは、多くの変数を持つデータを集約して主成分を作成する手法、多くの変数の情報をできるだけ損なわずに、少数の変数に縮小させることを目的とした手法。
次元削減の一つの手法。
寄与率を調べれば各成分の重要度が分かる、主成分を調べることで各成分の意味を推測することができるといった利点がある。
次元の呪い
機械学習において、「次元が増えると計算量や学習に必要なサンプル数が爆発的に増えて様々な不都合が生じる」という法則。 サポートベクターマシンとは サポートベクターマシン(SVM)
SVMとは もともとは2クラス分類のアルゴリズム。「マージンの最大化」というコンセプトのもと、2つのクラスを線形分離する。
代表的なパラメータにスラック変数がある。
カーネルトリックにより精度を向上させる、非線形問題を解くことができるようになるというメリットがある。
スラック変数とは スラック変数
SVMなどのアルゴリズムで、一部の誤分類を寛容にするため使用される変数。
カーネル法とは カーネル法、カーネルトリック
カーネルトリックとは SVMは、線形分離可能でないデータ(直線でないデータ)に対してもカーネル法を組み合わせることで決定境界を求めることができる。
(カーネル法=決定境界を非線形にする、非線形の決定境界を得るための手法)
データをあえて高次元空間に写像するための関数をカーネル関数という。
しかしそれには膨大な計算量が必要であるため、カーネルトリックという手法で計算量を現実的に削減しつつ、非線形分離を実現する。
ハイパーパラメータとは ハイパーパラメータ
学習前にエンジニアが調整しなければならない変数のこと。
一方、パラメータとは学習によって最適化される変数のこと。
パラメータとは パラメータ
パラメータとは、モデルの学習実行後に獲得される値を指しており、重みとも呼ばれる。
画像参照:機械学習の基礎 / キカガク グリッドサーチとは (ハイパーパラメータの)グリッドサーチ
ハイパーパラメータの候補がたくさんあるなかで最良のハイパーパラメータを探す方法。
事前に設定したハイパーパラメータの候補に対して、交差検証で精度を図り、最も精度が高かったハイパーパラメータの組み合わせを最良のハイパーパラメータとして採用する方式。
計算量が多くなるという欠点があるが、よく用いられている手法。
ベイス最適化とは ベイス最適化
ハイパーパラメータを含め最適化問題とするベイズ最適化が効率的なチューニング方法として注目をあびている。
これは過去の試行結果から次に行う範囲を確立分布を用いて計算する手法。
ハイパーパラメータの例
・隠れ層の数
・活性化関数
・学習率の調節を行う必要がある(勾配降下法)
ハイパーパラメータでないもの
・バイアス(バイアスはモデルのパラメータの一部のため) ディープラーニングとは
DeepLearningとは
DeepLearningとは ディープラーニング
ディープラーニングは、ディープニューラルネットワークを用いた機械学習。
層数を増やすと非常に複雑な関数を近似する能力をもつ。
欠点としては、「過学習や勾配消失問題を起こしやすい」、「事前に調整すべきパラメータが非常に多い」が挙げられる。
事前学習 ニューラルネットワークとは ニューラルネットワーク
DNNとは ニューラルネットワークとは
入力に対して重みづけを行い、それらとバイアスを足し合わせる処理を行った後、
活性化関数を用いて出力に変換を行う予測器であるニューロンを多層に組み合わせた予測器を指す。
出力が吐き出される層を出力層、それ以外の層を中間層または隠れ層という。
画像 ニューラルネットワークのイメージ 住宅価格の予測 / TECH BLOG 隠れ層とは 隠れ層(中間層とも呼ばれる)
入力層から情報を受け継ぎ、さまざまな計算を行うのが隠れ層。
隠れ層が増えると、複雑な関数を近似する能力が上がる。
DNNとは 計算規則
ディープニューラルネットワーク(DNN)が予測を行う際の計算規則。
データが入力層へと入力され、次の層とのコネクションに与えられた重みの総和をとり、バイアスを足す。
その後、活性化関数による非線形変換を加えた数値が、次の層のノードに引き渡される。
パーセプトロンとは パーセプトロン
パーセプトロンは、人間の脳神経回路を真似た学習モデルで、人工ニューロンとも呼ばれています。
神経細胞のニューロンの構造を模している。
基本的な構造は、あるデータの各変数を入力し、そのデータそれぞれに重みづけを行って足し上げ、その値がある閾値(しきいち)を超えたか否かによって分類を出力するもの。
データが適切に線形分離可能であるという前提のため、満たさない場合には答えが収束しないので注意が必要。
単純パーセプトロンとは 単純パーセプトロン
線形分離可能な(=1次関数を使って分離できる)問題であれば解ける。ステップ関数を使う。
単純パーセプトロンの限界は、多層にしてバックプロパゲーション(誤差逆伝搬学習法)を用いて学習すれば克服できることが示された。
多層パーセプトロンとは 多層パーセプトロン(MLP:Multilayer perceptron)
非線形分離も可能。これの層が深くなったやつがディープラーニング。
勾配消失問題とは 勾配消失問題
勾配消失とは 誤差の勾配を逆伝播する過程において、勾配の値が消失してしまい、入力層付近での学習が進まなくなる現象のこと。
これは隠れ層に使っていた活性化関数「シグモイド関数」が原因。
シグモイド関数は、微分値が最大でも0.25にしかならないため、掛け算していくと値がどんどん小さくなっていってしまう。
つまり伝播していく過程で誤差がどんどんなくなっていく。
誤差が小さいとモデルの重みを更新する値が小さくなってしまうので、学習が停止してしまう可能性が高くなる。
勾配消失問題に対処するための方法として、バッチ正規化(2015年に提案)や、あらかじめ良い重みの初期値を計算する事前学習、活性化関数にReLU(正規化線形関数)を利用する方法などがある。
勾配とは 勾配
イメージとしては、接戦の傾きのこと。
仮に今赤い点にいる場合、
勾配=赤い接線の傾き 勾配爆発問題とは 勾配爆発問題
勾配爆発とは 誤差逆伝播法のときに、誤差が大きくなっていき学習が収束しない問題。
自己符号化器とは オートエンコーダ(自己符号化器、自己符号化機) ※自己符号化器が正しいが検索用に念のため二つ残しておく
オートエンコーダとは 教師なし学習の一種(特徴量を抽出する)。
オートエンコーダーとは ジェフリー・ヒントンが提唱した勾配消失問題の解決策。可視層と隠れ層の2層からなるネットワーク。
隠れ層が入力の特徴を抽出した表現となる。
エンコーダとデコーダからなる。入力層と出力層の数はおなじだが、中間層のノード数はそれより少ない。
「正解ラベル」として入力自身を用いることで、次元削減ができる。
主に時限削減のために利用されることが多く、活性化関数に恒等写像を用いた場合の3層自己符号化器は、主成分分析(PCA)と同様の結果を返す。
自己符号化器を多層化すると、ディープニューラルネットワーク同様に勾配消失問題が生じるため、複雑な内部表現を得ることは困難だった。
この問題に対して2006年ごろにヒントンらは、
単層の自己符号化器に分割し入力層から繰り返し学習させる層ごとの貪欲法(=層ごとに学習をする必要がある)を積層自己符号化器に適用することで汎用的な自己符号化器の利用を可能とした。
また自己符号化器の代表的な応用例として、
・ノイズ除去
・ニューラルネットの事前学習
・異常検知 がある
積層オートエンコーダーとは 積層オートエンコーダー(ディープオートエンコーダー)
ディープオートエンコーダーとは ディープニューラルネットワークの全ての層を一気に学習させるのではなく、入力層に近い層から順番に学習させるという、逐次的な方法。
順番に学習していくことによって、それぞれの隠れ層の重みが調整される。
このオートエンコーダーを順番に学習していく手順のことを、事前学習(pre-training)と呼ぶ。
積層オートエンコーダは、事前学習と(後述の)ファインチューニングの工程で構成されている。
深層信念ネットワークとは 深層信念ネットワーク(deep belief networks)と制限付きボルツマンマシン
deepbeliefnetworksとは ジェフリー・ヒントンが提唱した手法の名前。事前学習を用いたディープラーニングの手法
制限付きボルツマンマシンとは
GPGPU
GPGPUとは CPUと異なり、様々なタスクをこなすのは不得意。同じような並列計算処理が大規模に行われる場合に、パワーを発揮する。画像目的以外の仕様に最適化されたGPUのことをGPGPUと呼ぶ。
GPGPUの開発をリードしたのはNVDIA社。あと、Google社のテンソル計算処理に最適化された演算装置は、TPUと呼ばれている
GPUとは GPU(Graphics Processing Unit)
・NVIDIA(エヌビディア)
RTXシリーズ
GeForceシリーズ
Hopperアーキテクチャ、Voltaアーキテクチャ
・AMD
Radeonシリーズ
データ量
バーニーおじさんのルール
「モデルのパラメーター数の10倍のデータが必要」という経験則
ディープラーニングの理論 活性化関数とは 活性化関数
ステップ関数とは
シグモイド関数とは
ReLUとは
ReLU関数とは
Leaky ReLUとは
Leaky ReLU関数とは 補足シート:活性化関数
tanhとは
tanh関数とは
ハイパボリックタンジェントとは
ソフトマックスとは
ソフトマックス関数とは
勾配降下法とは 勾配降下法
勾配に沿って降りていくことで解を探索する手法。
最適化(=損失関数、コスト関数、誤差関数を最小化すること)が目的。(訓練誤差を最小化する重み(パラメータ)を求めたい) 汎化誤差とは データの母集団に対する誤差の期待値は汎化誤差と呼ばれ、汎化誤差を最小化するパラメータを得ることが理想となる。
しかし勾配降下法には計算量が膨大になるという問題があり、これを避けるために誤差伝播法が利用される
汎化誤差は、バイアス、バリアンス、そしてノイズの3要素に分けることができる。 三つの要素 バイアスとは バイアス
予測値と真の値(=正解値)とのズレのこと。
バリアンスとは バリアンス
予測値の広がり(つまり「ばらつき誤差:Variance error」)のこと。
ノイズとは ノイズ
どうやっても減らすことができない誤差のこと。
損失とは 損失
「ニューラルネットワークによる予測値と正解値との差」のこと。ニューラルネットワークの予測値が変われば、損失も変わる。
よく使われる損失関数 損失関数にパラメータの二乗ノルムを加えるとL2正則化となる
回帰問題 平均二乗誤差関数
分類問題 交差エントロピー誤差関数
分布を直接学習する KLダイバージェンス
勾配降下法の手順
1.重みとバイアスを初期化する
2.ミニバッチをネットワークに入力し出力を得る
3.ネットワークの出力と正解ラベルとの誤差を計算する
4.誤差を減らすように重み(バイアス)を修正する
5.最適な重みやバイアスになるまで繰り返す バッチとは バッチ
データ全部のこと
勾配降下法の種類(最適化アルゴリズム) バッチ勾配降下法とは 勾配降下法は、利用するデータの量によって3種類に分けられる。
最急降下法とは ・バッチ勾配降下法(最急降下法) ・・・全データを使って関数の最小値を探索
確率的勾配降下法とは ・確率的勾配降下法(SGD) ・・・ランダムに抽出した1つのデータを使って関数の最小値を探索
SGDとは ・ミニバッチ勾配降下法 ・・・データの一部を利用してて関数の最小値を探索
ミニバッチ勾配降下法
手法 利用データ 計算時間 メリット デメリット
バッチ勾配降下法 全てのデータを利用 大 ・解への到達が早いことが多い ・メモリの使用量が多い
(最急降下法) ・結果が安定する ・局所解にハマりやすい
SGD 1つのデータを利用 小 ・メモリの使用量が少ない ・解への到達が遅いことがある
(確率的勾配降下法) ・オンライン学習が可能 ・外れ値の影響を大きく受ける
・局所解を回避できる可能性がある
ミニバッチ勾配降下法 一部のデータを利用 中 バッチ勾配降下法とSGDのそれぞれのメリットがある。 バッチ勾配降下法とSGDのそれぞれのデメリットがある。
勾配降下法の問題
・谷での振動
・プラトーへのトラップ
・局所的最適解への収束(ここが答えだと勘違いしちゃうこと)
↑これらの問題に対処するために、
学習率をパラメータに適用させることで自動的に学習率を調整することができるAdagradや
勾配の平均と分散をオンラインで推定し利用するAdamが利用されてきた。
上の勾配降下法からいくつかの改善を加えたものが広く使われている モメンタムとは ・モメンタム(モーメンタム)
モーメンタムとは 以前に適用した勾配の方向を現在のパラメータ更新にも影響させる。
AdaGradとは ・AdaGrad
勾配を2乗した値を蓄積し、すでに大きく講師されたパラメータほど、更新量(学習率)を小さくする方法。学習率をパラメータに適用させることで自動的に学習率を調整することができる。
RMSpropとは RMSprop
AdaGradにおける一度更新量が飽和した重みはもう更新されない欠点を、指数移動平均を蓄積することにより解決したもの。
RMSprop(オプティマイザ、二次モーメント・分散の値を使う) , モメンタム(オプティマイザ、移動平均を使う)
RMSprop + モメンタム =Adam
イテレーションとは イテレーション
イテレーションとは繰り返しや反復を意味し、機械学習では重みが更新された回数を表す。
エポックとは エポック
訓練データを何度学習に用いたか。
例えばデータが6万枚あった時、すべてのデータを一度に訓練することはなく、いくつかに分けて行われる。
その分けた1回1回がイテレーション。そして6万枚やるのを1エポックという。
また、1回1回100枚ずつやるにした場合、この100枚という数字はバッチサイズという。 逐次更新とは 逐次更新(逐次学習)
確率的勾配降下法とは イテレーションごとに1つずつサンプルを利用する。一つのデータに対して誤差を計算し、重みを逐一更新(これを確率的勾配降下法という)
オンライン処理とは ※逐次学習はオンライン処理とも呼ばれる。
ミニバッチ勾配降下法とは ミニバッチ更新(ミニバッチ学習)
イテレーションごとに一定のサンプルを利用する。一部の(ランダムに)サンプリングしたデータに対して誤差を計算し、重みを逐一更新(ミニバッチ勾配降下法)。
バッチ更新とは バッチ更新(バッチ学習)
バッチ学習とは イテレーションごとにすべてのサンプルを利用する。全ての訓練データに対して誤差を計算し、重みを更新。
【AI・機械学習】バッチ学習・オンライン学習・ミニバッチ学習|データ処理・投入方法の解説 学習率とは 学習率
勾配に沿って、一度にどれだけ降りていくか、を決めるハイパーパラメーター(計算時に指定する変数)のこと。
学習率が小さいとじわじわいくが、細かいところまでみれる。大きいとでこぼこにおちいることなく飛び越えることができるが、値が発散しやすい。
学習率が
小さい ・・・ じわじわいくが、細かいところまでみれる、収束が遅くなる
大きい ・・・ でこぼこにおちいることなく飛び越えることができるが、値が発散しやすい 局所最適解とは 局所最適解 と 大域最適解
大域最適解とは 見せかけの最適解を局所最適解、本当の最適解を大域最適解と呼ぶ。最初は学習率を大きく設定して、適切なタイミングで学習率の値を小さくしていく工夫が必要になる。
鞍点とは 鞍点(あんてん)
ディープラーニングでは次元が大きいので、鞍点にはまって抜け出せなくなることがあります。そのような停留状態をプラトーという。抜け出る手法としてAdamやRMSprop。
停留点とは 停留点
局所最適解でも大域最適解でもないのに勾配がゼロになる点のこと。例えば、山頂。
その他のテクニック ドロップアウトとは ドロップアウト
オーバーフィッティングを解消する手法で、エポック毎にランダムにニューロンをドロップアウトさせて計算する。毎回モデルが変わることになるため、これはアンサンブル学習の一種。
ドロップアウトを使うことで、過学習を防ぎ、汎化性能を高めることができる。
earlystoppingとは early stopping
過学習する前に、早めに学習を打ち切る方法。シンプルで、どんなモデルにも適用できる手法。ジェフリー・ヒントンは、”Beautiful FREE Lunch”と表現。
ノーフリーランチ定理とは ノーフリーランチ定理
「あらゆる問題で性能の良い汎用最適化戦略は理論上不可能」という定理。
正規化とは 正規化
データ全体の調整。いろいろ種類はあるのが、例えば、各特徴量を0~1の範囲に変換する処理。
標準化とは 標準化
各特徴量の平均を0、分散を1にする。すなわち、各特徴量を正規分布に従うように変換すること。各特徴量の分散をそろえておくことで、それぞれの特徴量の動きに対する感度を揃えられる。
バッチ正規化とは バッチ正規化
ディープラーニングの各層において、活性化関数を書ける前に伝播してきたデータを正規化する手法。これで、オーバーフィッティングしづらくなることが知られている。
ディープラーニングの具体的な手法 CNNとは CNN(畳み込みニューラルネットワーク・Convolutional Neural Network)
畳み込みニューラルネットワークとは 畳み込み層とプーリング層を積み重ねる順伝播型(逆伝播ではない)のディープニューラルネットワーク。
ConvolutionalNeuralNetworkとは 主に画像認識(画像処理)の分野で用いられる。
データを学習することで入力画像から特徴量を抽出しそれらを区別することができるようになる。
プーリング層によって、画像の特徴位置が多少変化しても許容されるため、変形に対して頑強になる。
CNNの元となったモデルはLeNet。
CNNの基本形
入力層 → 畳み込み層 → プーリング層 → 全結合層 → 出力層 → 確率判定 畳み込みとは 畳み込み(Convolution)
畳み込み層とは カーネルとも呼ばれるフィルタを用いて画像から特徴を抽出する操作のこと。
フィルタを画像の左上から順番に重ね合わせていき、画像とフィルタの値をそれぞれかけあわせたものの挿話をとった値を求めていく処理。
畳み込みによって新たに得られた二次元データを特徴マップと呼ぶ。
CNNでは、各フィルタをどのような値にすれば良いかを学習していくことになる。(このフィルタが、ニューラルネットワークでいうところの重みになる。)
この畳み込みの処理は、人間の視覚やが持つ局所受容野に対応していて、移動普遍性の獲得に貢献する。(但し、回転普遍性は持っていない。)
積和計算や活性化関数による変換を行う。
プーリングとは プーリング
画像サイズを規則に従って縮小する処理のこと。画像を鮮明にするわけではない。
サブサンプリングとは 決められた演算を行うだけで、ダウンサンプリングやサブサンプリングともよばれいる。
平均プーリングとは プーリング操作
最大プーリングとは 平均プーリング・・・周りの平均値で圧縮する
最大値プーリングとは 最大プーリング、最大値プーリング・・・周りの最大値で圧縮する
Lpプーリングとは Lpプーリング・・・周りの値をp乗しその標準偏差をとる
全結合層とは 全結合層
最後は、イヌやネコといった一次元の出力になるので、そういった層が必要。但し、最近のCNNでは、全結合層を用いないケースも大きい。
全結合層の代わりに、1つの特徴マップに1つのクラスを対応させることで分類を行うGlobal Average Poolongと呼ばれる処理を行うことが多いみたい。
パディングとは パディング
元の画像のまわりを固定値で埋めること。
ストライドとは ストライド
畳み込みのフィルターを動かす幅のこと。
LeNetとは LeNet
ヤン・ルカンによって作られたCNNのモデル。こちらは誤差逆伝播法を使いる。畳み込み層とプーリング層の2種類が交互に複数組み合わさる。
データ拡張とは データ拡張(data augmentation)
水増しとは 上下左右にずらしたり反転させたりする、データの「水増し」のこと。
例:きれいな画像を汚して水増しを行う
水増しする訓練データの加工は、画像の意味が変わらない程度におさえる必要がある。
ロバストとは ロバスト(ロバスト性)
ロバスト性とは ロバスト (robust) =日本語訳では頑健(がんけん)。
ロバストネスとは 環境変化や遺伝的変化に抗して,システムの状態を保持する性質。変化や外乱の影響の受けにくさ。という意味。
ディープラーニングの学習時間
ディープラーニングの学習には一般的に時間がかかるため、既存の学習済みモデルを利用したファインチューニングや転移学習という手法がある。
共通点は出力層の再学習を行うこと。 ファインチューニングとは ファインチューニング
学習済みモデルの全ての層の重みを微調整する手法。
モデルを再利用するため、一から学習するよりも短時間で少ないデータ・データが集まらない時でもモデルの構築が可能。
CNNの入力層に近い中間層では、タスクごとに比較的大きな差が生まれない汎用的な特徴量が学習されるためこの手法を用いることができる。
ファインチューニングは、学習済み層の学習率を低く設定する場合が多い。
転移学習とは 転移学習
学習済みモデルの重みは固定し、追加した層のみを使用して学習する手法。
画像参照:転移学習とは│コンパクトなデータ活用サイト
CNNは画像→特徴量を抽出する
特徴量(特徴マップ)→画像を生成する 逆畳み込みの構造を用いるタスクの例
・畳込み層の逆操作である「逆畳み込み層」 画像セグメンテーション
・プーリングの逆操作である「アンプーリング層」 ネオコグニトロンとは ネオコグニトロン
ネオコグニトロンは、1979年に福島邦彦によって提唱されたCNN(畳み込みニューラルネットワーク)。
人間の視覚野の働きを組み込んだ最初のモデル。
RNNとは RNN(リカレントニューラルネットワーク / Recurrent Neural Network) = 再起型ニューラルネットワーク
リカレントニューラルネットワークとは
RecurrentNeuralNetworkとは 内部に再帰構造を持ち、系列データを扱うために開発された。
閉路を持つニューラルネットワーク。
過去の情報を保持できる(一時的に記憶させることができる)ことから、系列データをうまく扱うことができる。
自然言語処理、音声処理などの時系列データへ幅広く応用されている。
ループ構造を持ったRNNの学習にはバックプロパゲーション(back-propagation)が使われる。そのため勾配消失問題が起きやすい。
最近はLSTM(この下に記述)などにより、勾配消失、勾配爆発を回避する方法が定着してきた。
RNNの一種であるLSTMは機械翻訳や画像からのキャプション生成などに応用できる。
画像説明(画像から説明文を生成)では、CNNからRNNに接続しキャプション(説明文)を生成する。
LSTMとGRU
RNNの一種であり、RNNの欠点であった「短絡的な情報しか保持できない」、「長い系列を遡るにつれて学習が困難になる」点を改良し、
長期的な情報を考慮して予測計算を行えるようにしたもの。
メモリーセル、入力ゲート、出力ゲート、忘却ゲートの4つがキーワード LSTMとは LSTM(Long Short Term Memory)
LSTMでは、抽出ゲートを含む LSTM Block を組み込む(=内部にゲート構造を持つ)ことで,長期間の系列情報に対しても勾配消失せずに学習を行うことができる。
ユルゲン・シュミットフーバーとゼップ・ホフレイターが提案。
LSTMは、その優れた性能から自然言語処理、音声認識、時系列データ解析など様々な分野で応用されている。
GRUとは GRU(Gated Recurrent Units)
LSTMをより簡素化したモデル。(ゲートを削減することで計算コストを削減)。
LSTMより計算量が少なく高速に学習を進めることができる。
深層教科学習とは 深層強化学習
強化学習と深層学習の手法を組み合わせたもの。
ディープニューラルネットワークを用いて行動価値を最大にする方策を効率的に計算することを目指す手法。
代表的な手法に、Deep-Q-Network(DQN)がある。
Deep-Q-Networkとは Deep-Q-Network
DQNとは DeepMind社のDeep-Q-Network(DQN)が有名。あの、Alpha Goも深層強化学習。
深層生成モデル
ディープラーニングは、認識・識別タスクだけでなく生成タスクにも応用され始めている。 VAEとは VAE(変分オートエンコーダー)
変分オートエンコーダーとは 画像が生成できる。
GANとは GAN(敵対的生成ネットワーク)
敵対的生成ネットワークとは 教師なし学習に用いられる手法。
偽物画像を作るGenerator(生成ネットワーク)と、偽物をきちんと見抜けるようにする学習をするDiscriminator(識別ネットワーク)という二つのネットワークで構成されている。
二つが切磋琢磨して、最終的には本物と見分けがつかないような贋作を作る。それぞれのネットワークにCNNを取り込んだものをDCGAN(Deep Convolutional GAN)という。
イアン・グッドフェロー(イアン=グッドフェロー)らが2014年に発表した論文。
ヤン・ルカンは「この10年で最もおもしろいアイデア」と絶賛。
ジェネレータ、ディスクリミネータ
人工知能の応用
研究分野 自然言語処理とは 言語処理分野
分野
機械翻訳、画像説明文生成 大幅な性能向上
自然言語処理 構文解析、意味解析 連続的な精度向上は見られるものの、基本的な手法は大きく変わらない
文脈解析、常識推論 実用的な制度は見込めない 分散表現とは 分散表現
単語を低次元の実数値ベクトルで表す表現のこと。だいたい50次元から300次元くらいで表現することが多い。
単語をベクトルで表現することができれば、単語の意味を定量的に把握することができるため、様々な処理に応用することができます。
Word2Vecとは Word2Vec
当時Googleに在籍していた研究者であるトマス・ミコロフ氏らにより提案され、自然言語処理に大きな技術的進展をもたらしたツール。
「単語の意味は、その周辺の単語によって決まる(=周辺語の予測)」という言語学の主張をニューラルネットワークとして実現したもの。
word2vecが、ベクトル空間モデルや単語埋め込みモデルとも呼ばれる。スキップグラム(Skip-Gram Model)とCBOWという2つの手法がある。
単語同士の意味の足し算や引き算のような演算を使える(まるで単語の意味を捉えられているかのような演算を行うことができる)。
有名な例:King – Man + Woman = Queen( King から Man を引き Woman を足すと Queen が得られる)
常識推論タスクとは 常識推論タスク
機械が知能を持っているか否かを判断することを目的とした知能テスト。
南カリフォルニア大学 Andrew Gordon(アンドリュー・ゴードン)の「COPA(Choice Of Plausible Alternative)」が有名。
また、Ernest DavisとHector Levesqueが定式化した「WSC」。「統計的手掛かりだけでは解けないような照応解析の問題が解けること」が知能を持つこととしてこれをテストの形にしたもの。
COPAとは COPAとは
前提 P と二つの文 A1, A2が与えられたとき,P の結果(または原因)としてふさわしい文を選ぶ問題のこと。
シーケンス2シーケンスとは シーケンス2シーケンス(Sequence to Sequence)
SequencetoSequenceとは 自動翻訳技術で用いられる。
ニューラルチューリングマシンとは ニューラルチューリングマシン(NTM)
NTMとは チューリングマシンをニューラルネットワークで実現する試み。
エルマンネットとは エルマンネット(エルマンのネットワーク)
エルマンのネットワークとは RNNの一種で、文法解析をするモデル。
形態素解析とは 形態素解析
テキストデータから文法・単語に基づき、言語で意味を持つ最小単位である形態素に分割し、その形態素の品詞を判定する技術。
自然言語処理は、次のようなフローで実行される。
(1) 形態素解析で文章を単語などの最小単位に切り分ける
(2) データのクレンジングにより不要な文字列を取り除く
(3) BoW (Bag-of-words)などを用いてベクトル形式に変換する ←Doc2Vecでない点に注意
bag-of-words・・・文章に単語が含まれているかどうかを考えてテストデータを数値かする
(4) TF-IDなどを用いて各単語の重要度を評価する。※TF-IDFとは、「文書の特徴」を表現するために「文書に含まれる単語の重要度」を考慮する概念 セマンティックウェブとは セマンティックウェブ
情報リソースに意味を付与することで、コンピュータで高度な意味処理を実現する。
意味ネットワークとは 意味ネットワーク
単語同士の意味関係をネットワークによって表現する。
統計的自然言語処理とは 統計的自然言語処理
言語処理に確率論的あるいは統計学的手法を用いる手法。
照応解析とは 照応解析
照応詞(代名詞や指示詞など)の指示対象を推定したり、省略された名詞句(ゼロ代名詞)を補完する処理のこと。
Encoder-Decoderネットワーク Encoder-Decoder ネットワーク
Encoder-Decoderモデル Encoder-Decoder モデルともいう。
エンコーダ・デコータネットワーク 「入出力を端として,中央部の次元を低くし,その中央部の左右で対称形を成すネットワーク構造」のこと。
エンコーダ・デコータモデル EncoderとDecoderが対称構造をなして,元の情報を変換・復元するネットワークのこと。
GNMTとは GNMT (Google’s Neural Machine Translation)
2016年 9月からGoogle翻訳で使用されている、機械学習を使った手法によるGoogleの翻訳システム。
最初は中国語⇔英語の翻訳、2016年11月からは日本語⇔英語に対応しています。
RNNLMとは RNNLM (再帰型ニューラル言語モデル)
再帰型ニューラル言語モデルとは Recurrent Neural Language Model(RNLM)。もしくは RNN言語モデル(RNNLM)とも呼ぶ。
直前の数個の単語を入力として,次の1単語を予測する。
情報をリレー形式で渡すことで文脈を読み取るというモデル。
「文が長くなりすぎると精度が下がる」という課題がある。
過生成や生成不足をしてしまうことが、問題点とされている。
過生成の例
入力:I have an apple and an orange
出力:私はりんごとりんごとりんごとオレンジを持っている
機械翻訳
機械翻訳では、人間の自然な言葉遣いから、出現した単語に続く単語を確率的に予測する言語モデルが用いられる。
それをニューラルネットワークで近似したニューラル機械翻訳モデルも増えてきている。 トピックモデルとは トピックモデル
自然言語処理の分野で用いられる統計的潜在意味解析の一つ。
「言葉の意味」を統計的に解析していく手法。
トピック=主題
代表的な手法としてLSI (Latent Semantic Index)、
Probabilistic Latent Semantic Indexing(PLSI)、
Latent Dirichlet Allocation(LDA)がある
LSIとは LSI (Latent Semantic Index、潜在的意味解析)
LatentSemanticIndexとは おなじ意味の単語をうまくまとめることで文書の情報量を凝縮して要点を強くする。
潜在的意味解析とは テキストデータに特異値分解を適用するもの。
PLSIとは PLSI(Probabilistic Latent Semantic Indexing)
トピックモデルにおいて、確率計算に基づいてトピックを推定する方法。
LSIの確率モデル化。
アスペクトモデルと呼ばれる統計的なモデルを用いる。
LDAとは LDA(Latent Dirichlet Allocation 潜在的ディリクレ配分法)
潜在的ディリクレ配分法とは 確率を使って複数の文書のトピックを明らかにする手法。
音声認識分野
WaveNet
音声合成と音声認識の両方を行うことができるモデル。 HMMとは HMM(隠れマルコフモデル)
隠れマルコフモデルとは 音声認識では、HMMという言語モデルを用いて、文章としての単語のつながりを確率的に表現して、文章の形を推測する。
1990年代の音声認識は、隠れマルコフモデルによる音自体を判別する音響モデルと、Nグラム法による語と語のつながりを判別する言語モデルの両方でできている。
しかしディープラーニングの登場とりわけRNNの登場により音響特徴量から音素、文字列、さらには単語列に直接変換するEnd to End(EndtoEnd)モデルというアプローチをとることが可能になり、
人的に前処理を行わなくても解析することが可能になった。
コーパスとは コーパス
AIが自然言語を扱い際に、使う文章を構造化し、データベース化したもの。
コーパスを活用することでネイティブが自然だと感じる言語に近づけることができるというメリットがある。
WERとは WER(Word Error Rate)
WordErrorRateとは 音声認識技術の一般的な評価尺度。
機械翻訳や音声認識などで使われており、エラー率なので低いほうがいい評価になる。
ロボティクス分野
強化学習
(1) 方策(ポリシー)ベース
(2) 行動価値関数ベース(Q関数ベース)
(3) モデルベース 一気通貫学習とは 一気通貫学習
ロボットの一連の動作を一つのニューラルネットワークで実現しようとする学習。
マルチモーダル学習とは マルチモーダル学習
互換や体性感覚といった複数の感覚の情報を組み合わせて処理すること。
マルチモーダルとは マルチモーダル
複数の情報を組み合わせるという意味。
産業への応用
自動運転
6段階の自動運転レベルの定義がある。
シート「自動運転」参照
その他の応用事例
事例:チャットボット
予め用意してある複数回答文から適切なものを選択して回答するタイプと、都度で回答文を生成するタイプがある
倫理と法律
過失の責任
AIには故意や過失という状態をあてはめられないため、AIの所有者が「不法行為責任」を負わなければいけない可能性がある。
AIの製造者は「製造物責任」を問われる可能性がある。ただし、「製造物責任」は動産にたいして問われるものであるため、プログラムとしてのAIは「製造物責任」の対象となる可能性は低い。
その他用語メモ
確率的モデル例:深層ボルツマンマシン
確定的モデル例:CNN、積層自己符号化器、再起型ニューラルネットワーク(RNN)、サポートベクターマシン、雑音除去自己符号化器 adversarialexampleとは adversarial example
学習済みのディープニューラルネットモデルを欺くように人工的に作られたサンプルのこと。
サンプルに対して微小な摂動(せつどう)を加えることで,作為的にモデルの誤認識を引き起こすことができる。
平滑化とは 平滑化
細かいノズルの影響を除去する。
ヒストグラム平均とは ヒストグラム平均
画素ごとの明るさをスケーリングする。
データセット MNISTとは MNIST ・・・ アメリカの国立標準技術研究所によって提供される手書き数字のデータベース
ImageNetとは ImageNet ・・・ 1400万枚の自然画像
ResNetとは ResNet ・・・ 求めたい関数と入力との差である残差を学習するようにした
物体検出とは 物体検出
画像内に含まれるとある物体を取り囲むようなボックスを推定するタスクを行うもの。
物体セグメンテーションとは 物体セグメンテーション
対象とする物体とその周囲の背景を境界まで切り分けるようなタスクを行うもの。
画像キャプションとは 画像キャプション生成
画像内に表示されている女性を認識し,「青い服を着てスマートフォンをいじっている」などのようにその対象が何をしているかを表示させることができるようになりつつある。
画像生成
2015 年に google 社が通常の画像をまるで夢に出てくるかのような不思議な画像に変換して表示する Deep Dream というプログラムを発表し話題を呼んだ。 残響抑圧とは 雑音・残響抑圧
音声を認識したい対象とそれ以外の雑音に分離する。
音素状態認識とは 音素状態認識
音声の周波数スペクトル、すなわち音響特徴量をインプットとして、音素状態のカテゴリに分類する。
EndtoEnd音声認識とは End to End 音声認識
音響特徴量から音素,音素から文字列,文字列から単語列に直接変換して言語モデルを学習するアプローチ。
end-to-endlearningとは end-to-end learning
ディープラーニングにおいて,1つの問題やタスクに対して,ネットワーク中の入力層(端)から出力層(端)までの全層の重みを,いっぺんに学習することを言う。
最小二乗法とは 最小二乗法
モデルの予測値と実データの差が最小になるような係数パラメータを求める方法。
符号を考えなくてよくなり計算がしやすくなる、異常値を考慮する必要がある。
最尤推定法とは 最尤推定法
ある係数パラメータが与えられたときに、モデルが実データを予測する確率(尤度・ゆうど)を最大化するような係数パラメータを求める方法。
欠損値とは 欠損値
リストワイズ法・・・欠損があるサンプルをそのまま削除してしまう方法。データの偏りがないか注意する
回帰補完・・・回帰モデルを作成し、欠測値を予測することで補完する方
数値への変換(数値変換)
マッピング・・・ドリンクのS、M、Lなどの順序をもつ文字列のカテゴリデータの場合、それぞれの値に対応する数値を辞書型データで用意し、数値に変化する方法
ワンホットエンコーディング・・・順序を持たない名義特徴型のカテゴリーデータについては、各変数に対応したダミー変数を新たに作り出す方法
AIの議論
AI が実世界における抽象概念を理解し,知識処理を行う上では,身体性を通じた高レベルの身体知を獲得し、
次に身体知を通じて言語の意味理解を促し,抽象概念・知識処理へと至るのではないかということが議論されている。 クラス分類とは クラス分類
層を沢山重ねた深い層であってもうまく学習ができるように、出力を入力と入力からの差分の和としてモデリングしたネットワークの枠組み。
ResNet が提案され高い精度の識別性能を誇っている。
ライブラリ
Numpy ・・・ 線形代数の計算に強いライブラリ
sciket-learn ・・・ 機械学習全般に強いライブラリ
Scipy ・・・ 確立統計に強いライブラリ
seaborn ・・・ グラフを描くためのライブラリ
Microsoftの音声認識
CNNとLSTMを組み合わせるモデルで音声認識の性能を向上させた(例:Cortana)。 Definebyrunとは Define by run
計算グラフ(ニューラルネットの構造)の構築を、データを流しながら行います。
AI生成物
人間の創作的寄与がなければ、当該「AI生成物」は AIが自律的に生成した「AI 創作物」であると整理され、現行の著作権法上は著作物と認められない。
著作物の利用
機械学習のために画像(著作物)を収集・加工・利用することはもちろん、収集した学習用データを第三者に提供(販売・譲渡など)することは、
著作権法第30条の4第2号において認められています。
特許法下の、創作の3ステップ
「課題の設定(課題設定)」
「解決手段候補選択」
「実効性評価」
モデル圧縮 蒸留モデルとは 蒸留モデル
すでに学習されているモデル(教師モデル)を利用して、より小さくシンプルなモデル(生徒モデル)を学習させる手法。
これにより過学習を緩和することができる。
キーワード 小さなネットワーク、小さく、シンプルなモデル
派生モデルとは 派生モデル
既存のモデルの構造が明らかである場合に、異なるデータを使って再学習したもの。
総務省 リスクの4分類
AI自身のリスク
例:AIのアルゴリズムがブラックボックス化し、人間の制御ができなくなってしまう
AIに関わる人間のリスク
例:人間がAIを利用した無差別○人を行う
社会的婦のインパクト
例:AIが人々の職を奪ってしまう
法律、社会の在り方
例:自動運転が引き起こした事故は誰が責任を負うのか
AAA - IPresidential Panel on Long-Term AI Futures:2008-2009 Study
エリック・ホロヴィッツ主導。
AIの成功の時期、課題や機会を検討。
Microsoft AI開発原則(2016年)
人間の拡張するもの
透明性の確保
多様性の確保
プライバシーの保護
説明責任の義務
偏見の排除を提唱 偏微分とは 偏微分
特定の文字以外定数とみなして微分したもののこと。
をx 以外を定数とみなして(つまり y を定数とみなして)」微分すると,2x+y となります。
ドローンを飛ばす許可
150m以上の高さの空域では、許可が必要。
その他、ヒト・モノから30m以内の飛行の禁止(改正航空法H27)。
米国
Preparing for the Future of Artificial Intelligence ほか
倫理的リスクの取り組み。
MOOCs(Massive Open Online Courses 大規模公開オンライン講)
オンラインで公開された無料の講座を受講し、修了条件を満たすと修了証が取得できるという教育サービスのこと。
AIの人材不足や人材育成の試みとして期待が寄せられている。
経済戦略
日本 ・・・ 新産業構造ビジョン
英国 ・・・ RAS 2020 戦略
ドイツ ・・・ デジタル戦略2025
中国 ・・・ インターネットプラスAI3年行動実施法案 {kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント