
pandasはPythonでのデータ分析ツールとして最も活用されており、データの入手や加工など多くのデータ処理に使われています。
pandasの概要
pandasはNumpyを基盤にシリーズ(Series)とデータフレーム(DataFrame)というデータ型を提供しています。
pandasを利用するには以下のようにインポートします。
import pandas as pdSeriesとは
Seriesは一次元データで、Seriesオブジェクトを作るにはSeriesを使います。
ser = pd.Series([10,20,30,40])
ser0 10
1 20
2 30
3 40
dtype: int64DataFrameとは
DataFrameは二次元データで、DataFrameオブジェクトを作るにはDataFrameを使います。
df = pd.DataFrame([[10,"a",True],
[20,"b",False],
[30,"c",True],
[40,"d",False]])
df 0 1 2
0 10 a True
1 20 b False
2 30 c True
3 40 d FalseNumpyのarange関数を使って20×4行列のデータを生成し、DataFrameを作ります。
import numpy as np
df = pd.DataFrame(np.arange(80).reshape((20,4)))
df 0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
5 20 21 22 23
6 24 25 26 27
7 28 29 30 31
8 32 33 34 35
9 36 37 38 39
10 40 41 42 43
11 44 45 46 47
12 48 49 50 51
13 52 53 54 55
14 56 57 58 59
15 60 61 62 63
16 64 65 66 67
17 68 69 70 71
18 72 73 74 75
19 76 77 78 79headメソッドで先頭3行のみ取得
df.head(3)0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11tailメソッドで末尾3行のみ取得
df.tail(3)0 1 2 3
17 68 69 70 71
18 72 73 74 75
19 76 77 78 79DataFrameのサイズを知るには、shapeを使います。
df.shape(20, 4)インデックス・カラム名
DataFrameではインデックス名(行の名前)やカラム名(列の名前)を指定できます。
df = pd.DataFrame(np.arange(6).reshape((3,2)))
df 0 1
0 0 1
1 2 3
2 4 5df.index = ["01","02","03"]
df.columns = ["A","B"]
df A B
01 0 1
02 2 3
03 4 5DataFrame作成時に指定することもできます。
named_df = pd.DataFrame(np.arange(6).reshape((3,2)),
index=["01","02","03"],
columns = ["A","B"])
named_df A B
01 0 1
02 2 3
03 4 5辞書(dict)形式でDataFrameを作ることもできます。
カラム名だけを指定し、インデックス名は連番で割り当てられます。
pd.DataFrame({"A":[0,2,4],"B":[1,3,5]}) A B
0 0 1
1 2 3
2 4 5データの抽出
df = pd.DataFrame(np.arange(12).reshape((4,3)),
index=["01","02","03","04"],
columns = ["A","B","C"])
df A B C
01 0 1 2
02 3 4 5
03 6 7 8
04 9 10 11カラム名を指定して抽出します。
df["B"]01 1
02 4
03 7
04 10
Name: B, dtype: int32df[["B","C"]] B C
01 1 2
02 4 5
03 7 8
04 10 11インデックス値を指定して抽出します。
インデックス番号の0と1を抽出
df[:2]A B C
01 0 1 2
02 3 4 5インデックス番号の2と3を抽出
df[2:]A B C
03 6 7 8
04 9 10 11locとiloc
Pandasのlocとilocは値を抽出するためのメソッドです。
locは行名もしくは列名を指定することで特定の値を抽出できます。
df.loc[:,:] A B C
01 0 1 2
02 3 4 5
03 6 7 8
04 9 10 11カラム方向を指定して抽出
df.loc[:,"A"]01 0
02 3
03 6
04 9
Name: A, dtype: int32df.loc[:,["A","B"]] A B
01 0 1
02 3 4
03 6 7
04 9 10インデックス方向を指定して抽出
df.loc["01",:]A 0
B 1
C 2
Name: 01, dtype: int32df.loc[["01","03"],:] A B C
01 0 1 2
03 6 7 8インデックスとカラムを両方指定
df.loc[["01","03"],["A","B"]]A B
01 0 1
03 6 7ilocはindexを指定することで特定の値を抽出できます。
インデックス番号とカラム番号で抽出します。
A B C
01 0 1 2
02 3 4 5
03 6 7 8
04 9 10 11df.iloc[1,1]4df.iloc[1:,1]02 4
03 7
04 10
Name: B, dtype: int32df.iloc[1:,:2] A B
02 3 4
03 6 7
04 9 10データの読み込み・書き込み
データの読み込み(CSV)
事前に準備した来客数と売上のデータのcsvファイルを読み込みます。
df = pd.read_csv("C:/data/data.csv",encoding="utf-8")
df 日付 売上 来客数
0 2023-01-01 69989 51
1 2023-01-02 78302 70
2 2023-01-03 53671 25
3 2023-01-04 86240 26
4 2023-01-05 74553 89
5 2023-01-06 49224 21
・・・データの読み込み(Excel)
df = pd.read_excel("C:/data/data.xlsx")
df日付 売上 来客数
0 2023-01-01 69989 51
1 2023-01-02 78302 70
2 2023-01-03 53671 25
3 2023-01-04 86240 26
4 2023-01-05 74553 89
5 2023-01-06 49224 21
・・・webサイトのHTMLから表を取得
下記webサイトのHTML内にあるtable要素を抜き出します。
https://ja.wikipedia.org/wiki/トップレベルドメイン一覧
url ="https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%83%E3%83%97%E3%83%AC%E3%83%99%E3%83%AB%E3%83%89%E3%83%A1%E3%82%A4%E3%83%B3%E4%B8%80%E8%A6%A7"
tables = pd.read_html(url)
len(tables)40ページ内に40個のテーブルがあることが分かりました。
インデックスを指定して対象のテーブルを抽出します。
df = tables[1]
df
データの書き込み(CSV)
データの書き込みは、to_csvを使います。
df.to_csv("C:/data/data.csv")データの書き込み(Excel)
df.to_excel("C:/data/data.xlsx")データの再利用
pickleモジュールは、Pythonのオブジェクトを直列化し、ファイルへの書き込み及び読み込みが可能です。
to_pickleメソッドはファイルに書き出します。
df.to_pickle("C:/data/write_df.pickle")read_pickleメソッドはpickle形式に直列化されたデータを読み込むことが可能です。
df = pd.read_pickle("C:/data/write_df.pickle")データの整形
まずは使用するデータを読み込みます。
df = pd.read_excel("C:/data/data.xlsx")
df 日付 売上 来客数
0 2023-01-01 69989 51
1 2023-01-02 78302 70
2 2023-01-03 53671 25
3 2023-01-04 86240 26
4 2023-01-05 74553 89
5 2023-01-06 49224 21
・・・売上が50000以上の条件で抽出してみます。
df["売上"] >= 500000 True
1 True
2 True
3 True
4 True
5 False
・・・このboolean型のSeriesをDataFrameに当てはめて、Trueの行だけ抽出できます。
df_selected = df[df["売上"] >= 50000]
df_selected 日付 売上 来客数
0 2023-01-01 69989 51
1 2023-01-02 78302 70
2 2023-01-03 53671 25
3 2023-01-04 86240 26
4 2023-01-05 74553 89
6 2023-01-07 93566 67
7 2023-01-08 52820 64
8 2023-01-09 76983 37
13 2023-01-14 83898 69
14 2023-01-15 58561 34
18 2023-01-19 87110 84
19 2023-01-20 74743 70
20 2023-01-21 99073 40
21 2023-01-22 80673 41
22 2023-01-23 68824 21
24 2023-01-25 52180 79
25 2023-01-26 93228 74df_selected.shape(17, 3)また、queryメソッドを使ってデータを抽出することができます。
df.query('売上>= 50000 and 来客数<= 60') 日付 売上 来客数
0 2023-01-01 69989 51
2 2023-01-03 53671 25
3 2023-01-04 86240 26
8 2023-01-09 76983 37
14 2023-01-15 58561 34
20 2023-01-21 99073 40
21 2023-01-22 80673 41
22 2023-01-23 68824 21データ型変換
まず現在のデータ型を確認します。
df.dtypes日付 object
売上 int64
来客数 int64
dtype: object現在、日付カラムは文字列として扱われているので、applyメソッドを使って一括でdatetime型に変換してみます。
カラム日付に対して、applyメソッドを使ってデータ変換し、dateカラムに挿入しています。
df.loc[:,'date']=df.loc[:,'日付'].apply(pd.to_datetime)
df.loc[:,'date']0 2023-01-01
1 2023-01-02
2 2023-01-03
3 2023-01-04
4 2023-01-05
5 2023-01-06
・・・
Name: date, dtype: datetime64[ns]df 日付 売上 来客数 date
0 2023-01-01 69989 51 2023-01-01
1 2023-01-02 78302 70 2023-01-02
2 2023-01-03 53671 25 2023-01-03
3 2023-01-04 86240 26 2023-01-04
4 2023-01-05 74553 89 2023-01-05
5 2023-01-06 49224 21 2023-01-06dateカラムが追加されています。
次に売上をastypeメソッドを使ってfloat型に変換してみます。
df.loc[:,"売上"]=df.loc[:,"売上"].astype(np.float32)インデックスにdateカラムの値を設定してみます。
df=df.set_index("date")
df.head() 日付 売上 来客数
date
2023-01-01 2023-01-01 69989 51
2023-01-02 2023-01-02 78302 70
2023-01-03 2023-01-03 53671 25
2023-01-04 2023-01-04 86240 26
2023-01-05 2023-01-05 74553 89並べ替え
sort_valuesメソッドを使って、売上で並べ替えます。デフォルトは昇順です。
df.sort_values(by="売上") 日付 売上 来客数
date
2023-01-17 2023-01-17 3682 57
2023-01-28 2023-01-28 15228 87
2023-01-18 2023-01-18 16169 10
2023-01-16 2023-01-16 16743 68
2023-01-13 2023-01-13 22210 84
・・・降順に並べ替えます。
df.sort_values(by="売上",ascending=False) 日付 売上 来客数
date
2023-01-21 2023-01-21 99073 40
2023-01-07 2023-01-07 93566 67
2023-01-26 2023-01-26 93228 74
2023-01-19 2023-01-19 87110 84
2023-01-04 2023-01-04 86240 26
・・・不要なカラムの削除
日付カラムが不要なためdropメソッドを使って削除します。
axisはインデックス値を指定します。
df=df.drop("日付",axis=1)
df 売上 来客数
date
2023-01-01 69989 51
2023-01-02 78302 70
2023-01-03 53671 25
2023-01-04 86240 26
2023-01-05 74553 89組み合わせデータの挿入
カラム同士の計算結果を新たなカラムに挿入することができます。
売上/来客数のカラムを作り挿入します。
df.loc[:,"売上/来客数"]=df.loc[:,"売上"]/df.loc[:,"来客数"]
df売上 来客数 売上/来客数
date
2023-01-01 69989 51 1372.333333
2023-01-02 78302 70 1118.600000
2023-01-03 53671 25 2146.840000
2023-01-04 86240 26 3316.923077
2023-01-05 74553 89 837.674157
・・・ここで計算を関数化したプログラムを作ってみます。
新たに売上指数カラムを作ります。
売上/来客数が1000以下をLow、1000以上2000以下をMid、3000以上をHighとします。
sales_judgeという関数を定義します。
def sales_judge(sa):
if sa <= 1000:
return "Low"
elif 1000 < sa <= 2000:
return "Mid"
else:
return "High"df.loc[:,"売上指数"]=df.loc[:,"売上/来客数"].apply(sales_judge)
df 売上 来客数 売上/来客数 売上指数
date
2023-01-01 69989 51 1372.333333 Mid
2023-01-02 78302 70 1118.600000 Mid
2023-01-03 53671 25 2146.840000 High
2023-01-04 86240 26 3316.923077 High
2023-01-05 74553 89 837.674157 Lowpickleを使いファイルに保存しておきます。
df.to_pickle("C:/data/sales.xlsx")ここで売上指数に入っている[“High”,”Mid”,”Low”]のデータを3カラムに分割し「True」「False」で表示するようget_dummies関数を使って作成してみます。
get_dummies関数
文字列でカテゴリー分けされた性別などのデータを、男性を0、女性を1のように変換したり、多クラスの特徴量をone-hot表現に変換したりできる。機械学習の前処理として行うことが多い。
df_moved=pd.get_dummies(df.loc[:,"売上指数"],prefix="売上")
df_moved 売上_High 売上_Low 売上_Mid
date
2023-01-01 False False True
2023-01-02 False False True
2023-01-03 True False False
2023-01-04 True False False
2023-01-05 False True False
・・・ファイルを保存しておきます。
df_moved.to_pickle("C:/data/sales_moved.pickle")時系列データ
1ヵ月分のデータを作る
1ヵ月分の日付の配列を開始日及び終了日を設定して作成します。
dates=pd.date_range(start="2023-03-01",end="2023-03-31")
datesDatetimeIndex(['2023-03-01', '2023-03-02', '2023-03-03', '2023-03-04',
'2023-03-05', '2023-03-06', '2023-03-07', '2023-03-08',
'2023-03-09', '2023-03-10', '2023-03-11', '2023-03-12',
'2023-03-13', '2023-03-14', '2023-03-15', '2023-03-16',
'2023-03-17', '2023-03-18', '2023-03-19', '2023-03-20',
'2023-03-21', '2023-03-22', '2023-03-23', '2023-03-24',
'2023-03-25', '2023-03-26', '2023-03-27', '2023-03-28',
'2023-03-29', '2023-03-30', '2023-03-31'],
dtype='datetime64[ns]', freq='D')完成した日付の配列をインデックスにしたDateFrameを作り、データに乱数を設定します。
import random
np.random.seed(1230)
df=pd.DataFrame(np.random.randint(1,30,31),index=dates,columns=["乱数"])
df 乱数
2023-03-01 28
2023-03-02 28
2023-03-03 2
2023-03-04 10
2023-03-05 23
・・・1年分365日のデータを作る
dates=pd.date_range(start="2023-01-01",periods=365)
datesDatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10',
...
'2023-12-22', '2023-12-23', '2023-12-24', '2023-12-25',
'2023-12-26', '2023-12-27', '2023-12-28', '2023-12-29',
'2023-12-30', '2023-12-31'],
dtype='datetime64[ns]', length=365, freq='D')完成した日付の配列をインデックスにしたDateFrameを作り、データに乱数を設定します。
np.random.seed(1230)
df=pd.DataFrame(np.random.randint(1,31,365),index=dates,columns=["乱数"])
df 乱数
2023-01-01 28
2023-01-02 30
2023-01-03 28
2023-01-04 2
2023-01-05 10
... ...
2023-12-27 6
2023-12-28 9
2023-12-29 24
2023-12-30 19
2023-12-31 21
365 rows × 1 columns月平均のデータにする
freq=’M’ → 月を指定
freq=’Y’ → 年を指定
df.groupby(pd.Grouper(freq='M')).mean() 乱数
2023-01-31 15.354839
2023-02-28 14.678571
2023-03-31 15.612903
2023-04-30 14.933333
2023-05-31 16.290323
2023-06-30 14.533333
2023-07-31 14.225806
2023-08-31 16.193548
2023-09-30 14.466667
2023-10-31 15.322581
2023-11-30 17.300000
2023-12-31 14.548387次の例では、引数のカラムを乱数に固定して、resampleメソッドを使い毎月に平均値を出力しています。
df.loc[:,"乱数"].resample('M').mean()2023-01-31 15.354839
2023-02-28 14.678571
2023-03-31 15.612903
2023-04-30 14.933333
2023-05-31 16.290323
2023-06-30 14.533333
2023-07-31 14.225806
2023-08-31 16.193548
2023-09-30 14.466667
2023-10-31 15.322581
2023-11-30 17.300000
2023-12-31 14.548387
Freq: M, Name: 乱数, dtype: float64複雑な条件のインデックス
1年分の日曜日の日付のデータを作成します。W-SUNは週ごとの日曜日を指定している。
pd.date_range(start="2023-01-01",end="2023-12-31",freq="W-SUN")DatetimeIndex(['2023-01-01', '2023-01-08', '2023-01-15', '2023-01-22',
'2023-01-29', '2023-02-05', '2023-02-12', '2023-02-19',
'2023-02-26', '2023-03-05', '2023-03-12', '2023-03-19',
'2023-03-26', '2023-04-02', '2023-04-09', '2023-04-16',
'2023-04-23', '2023-04-30', '2023-05-07', '2023-05-14',
'2023-05-21', '2023-05-28', '2023-06-04', '2023-06-11',
'2023-06-18', '2023-06-25', '2023-07-02', '2023-07-09',
'2023-07-16', '2023-07-23', '2023-07-30', '2023-08-06',
'2023-08-13', '2023-08-20', '2023-08-27', '2023-09-03',
'2023-09-10', '2023-09-17', '2023-09-24', '2023-10-01',
'2023-10-08', '2023-10-15', '2023-10-22', '2023-10-29',
'2023-11-05', '2023-11-12', '2023-11-19', '2023-11-26',
'2023-12-03', '2023-12-10', '2023-12-17', '2023-12-24',
'2023-12-31'],
dtype='datetime64[ns]', freq='W-SUN')1週間単位で乱数をまとめます。
df_year=pd.DataFrame(df.groupby(pd.Grouper(freq='W-SUN')).sum(),columns=['乱数'])
df_year 乱数
2023-01-01 28
2023-01-08 99
2023-01-15 78
2023-01-22 138
2023-01-29 97
・・・欠損値処理
欠損値とはNaNで表示されるものでデータが入っていない項目です。
欠損値が存在すると予期せぬ計算結果になる可能性があるため、欠損値を処理しておく必要があります。
import pandas as pd
df_deficit=pd.read_csv("C:/data/data.csv",encoding="utf-8",index_col='日付',parse_dates=True)
df_deficit売上 来客数
日付
2023-01-01 69989.0 51.0
2023-01-02 78302.0 70.0
2023-01-03 NaN NaN
2023-01-04 86240.0 26.0
2023-01-05 74553.0 89.0
2023-01-06 49224.0 21.0
2023-01-07 NaN NaN
2023-01-08 52820.0 64.0
2023-01-09 76983.0 37.0
2023-01-10 33345.0 60.0
2023-01-11 46629.0 73.0
2023-01-12 49661.0 47.0
2023-01-13 22210.0 84.0
2023-01-14 83898.0 69.0
2023-01-15 58561.0 34.0
2023-01-16 16743.0 68.0
2023-01-17 3682.0 57.0
2023-01-18 16169.0 10.0
2023-01-19 87110.0 84.0
2023-01-20 74743.0 70.0
2023-01-21 99073.0 40.0
2023-01-22 80673.0 41.0
2023-01-23 68824.0 21.0
2023-01-24 48194.0 31.0
2023-01-25 52180.0 79.0
2023-01-26 93228.0 74.0
2023-01-27 48630.0 69.0
2023-01-28 15228.0 87.0
2023-01-29 33949.0 17.0
2023-01-30 39738.0 50.0dropnaメソッドを使って欠損値の行を削除します。
df_deficit_drop=df_deficit.dropna()
df_deficit_drop 売上 来客数
日付
2023-01-01 69989.0 51.0
2023-01-02 78302.0 70.0
2023-01-04 86240.0 26.0
2023-01-05 74553.0 89.0
2023-01-06 49224.0 21.0
2023-01-08 52820.0 64.0
2023-01-09 76983.0 37.0
2023-01-10 33345.0 60.0
2023-01-11 46629.0 73.0
2023-01-12 49661.0 47.0
2023-01-13 22210.0 84.0
2023-01-14 83898.0 69.0
2023-01-15 58561.0 34.0
2023-01-16 16743.0 68.0
2023-01-17 3682.0 57.0
2023-01-18 16169.0 10.0
2023-01-19 87110.0 84.0
2023-01-20 74743.0 70.0
2023-01-21 99073.0 40.0
2023-01-22 80673.0 41.0
2023-01-23 68824.0 21.0
2023-01-24 48194.0 31.0
2023-01-25 52180.0 79.0
2023-01-26 93228.0 74.0
2023-01-27 48630.0 69.0
2023-01-28 15228.0 87.0
2023-01-29 33949.0 17.0
2023-01-30 39738.0 50.0fillnaメソッドに0を設定して欠損値に0を代入します。
df_deficit_fillna=df_deficit.fillna(0)
df_deficit_fillna 売上 来客数
日付
2023-01-01 69989.0 51.0
2023-01-02 78302.0 70.0
2023-01-03 0.0 0.0
2023-01-04 86240.0 26.0
2023-01-05 74553.0 89.0
2023-01-06 49224.0 21.0
2023-01-07 0.0 0.0
2023-01-08 52820.0 64.0
2023-01-09 76983.0 37.0
2023-01-10 33345.0 60.0
2023-01-11 46629.0 73.0
2023-01-12 49661.0 47.0
2023-01-13 22210.0 84.0
2023-01-14 83898.0 69.0
2023-01-15 58561.0 34.0
2023-01-16 16743.0 68.0
2023-01-17 3682.0 57.0
2023-01-18 16169.0 10.0
2023-01-19 87110.0 84.0
2023-01-20 74743.0 70.0
2023-01-21 99073.0 40.0
2023-01-22 80673.0 41.0
2023-01-23 68824.0 21.0
2023-01-24 48194.0 31.0
2023-01-25 52180.0 79.0
2023-01-26 93228.0 74.0
2023-01-27 48630.0 69.0
2023-01-28 15228.0 87.0
2023-01-29 33949.0 17.0
2023-01-30 39738.0 50.0fillnaメソッドにmethod=”ffill”を設定して欠損値を1つ手前の値で補完します。
df_deficit_fill=df_deficit.fillna(method="ffill")
df_deficit_fill売上 来客数
日付
2023-01-01 69989.0 51.0
2023-01-02 78302.0 70.0
2023-01-03 78302.0 70.0
2023-01-04 86240.0 26.0
2023-01-05 74553.0 89.0
2023-01-06 49224.0 21.0
2023-01-07 49224.0 21.0
2023-01-08 52820.0 64.0
2023-01-09 76983.0 37.0
2023-01-10 33345.0 60.0
2023-01-11 46629.0 73.0
2023-01-12 49661.0 47.0
2023-01-13 22210.0 84.0
2023-01-14 83898.0 69.0
2023-01-15 58561.0 34.0
2023-01-16 16743.0 68.0
2023-01-17 3682.0 57.0
2023-01-18 16169.0 10.0
2023-01-19 87110.0 84.0
2023-01-20 74743.0 70.0
2023-01-21 99073.0 40.0
2023-01-22 80673.0 41.0
2023-01-23 68824.0 21.0
2023-01-24 48194.0 31.0
2023-01-25 52180.0 79.0
2023-01-26 93228.0 74.0
2023-01-27 48630.0 69.0
2023-01-28 15228.0 87.0
2023-01-29 33949.0 17.0
2023-01-30 39738.0 50.0fillnaメソッドにdf_deficit.mean()を与えることで欠損値を他の値の平均値で補完できます。
df_deficit_fillmean=df_deficit.fillna(df_deficit.mean())
df_deficit_fillmean 売上 来客数
日付
2023-01-01 69989.000000 51.000000
2023-01-02 78302.000000 70.000000
2023-01-03 55734.964286 54.392857
2023-01-04 86240.000000 26.000000
2023-01-05 74553.000000 89.000000
2023-01-06 49224.000000 21.000000
2023-01-07 55734.964286 54.392857
2023-01-08 52820.000000 64.000000
2023-01-09 76983.000000 37.000000
2023-01-10 33345.000000 60.000000
2023-01-11 46629.000000 73.000000
2023-01-12 49661.000000 47.000000
2023-01-13 22210.000000 84.000000
2023-01-14 83898.000000 69.000000
2023-01-15 58561.000000 34.000000
2023-01-16 16743.000000 68.000000
2023-01-17 3682.000000 57.000000
2023-01-18 16169.000000 10.000000
2023-01-19 87110.000000 84.000000
2023-01-20 74743.000000 70.000000
2023-01-21 99073.000000 40.000000
2023-01-22 80673.000000 41.000000
2023-01-23 68824.000000 21.000000
2023-01-24 48194.000000 31.000000
2023-01-25 52180.000000 79.000000
2023-01-26 93228.000000 74.000000
2023-01-27 48630.000000 69.000000
2023-01-28 15228.000000 87.000000
2023-01-29 33949.000000 17.000000
2023-01-30 39738.000000 50.000000データ連結
DataFrame同士の連結を行います。
まずはpickleで保存したデータを読み込みます。
df=pd.read_pickle("C:/data/sales.pickle")
df売上 来客数 売上/来客数 売上指数
date
2023-01-01 69989 51 1372.333333 Mid
2023-01-02 78302 70 1118.600000 Mid
2023-01-03 53671 25 2146.840000 High
2023-01-04 86240 26 3316.923077 High
2023-01-05 74553 89 837.674157 Low
2023-01-06 49224 21 2344.000000 High
2023-01-07 93566 67 1396.507463 Mid
2023-01-08 52820 64 825.312500 Low
2023-01-09 76983 37 2080.621622 High
2023-01-10 33345 60 555.750000 Low
2023-01-11 46629 73 638.753425 Low
2023-01-12 49661 47 1056.617021 Mid
2023-01-13 22210 84 264.404762 Low
2023-01-14 83898 69 1215.913043 Mid
2023-01-15 58561 34 1722.382353 Mid
2023-01-16 16743 68 246.220588 Low
2023-01-17 3682 57 64.596491 Low
2023-01-18 16169 10 1616.900000 Mid
2023-01-19 87110 84 1037.023810 Mid
2023-01-20 74743 70 1067.757143 Mid
2023-01-21 99073 40 2476.825000 High
2023-01-22 80673 41 1967.634146 Mid
2023-01-23 68824 21 3277.333333 High
2023-01-24 48194 31 1554.645161 Mid
2023-01-25 52180 79 660.506329 Low
2023-01-26 93228 74 1259.837838 Mid
2023-01-27 48630 69 704.782609 Low
2023-01-28 15228 87 175.034483 Low
2023-01-29 33949 17 1997.000000 Mid
2023-01-30 39738 50 794.760000 Low
df_moved=pd.read_pickle("C:/data/sales_moved.pickle")
df_moved 売上_High 売上_Low 売上_Mid
date
2023-01-01 False False True
2023-01-02 False False True
2023-01-03 True False False
2023-01-04 True False False
2023-01-05 False True False
2023-01-06 True False False
2023-01-07 False False True
2023-01-08 False True False
2023-01-09 True False False
2023-01-10 False True False
2023-01-11 False True False
2023-01-12 False False True
2023-01-13 False True False
2023-01-14 False False True
2023-01-15 False False True
2023-01-16 False True False
2023-01-17 False True False
2023-01-18 False False True
2023-01-19 False False True
2023-01-20 False False True
2023-01-21 True False False
2023-01-22 False False True
2023-01-23 True False False
2023-01-24 False False True
2023-01-25 False True False
2023-01-26 False False True
2023-01-27 False True False
2023-01-28 False True False
2023-01-29 False False True
2023-01-30 False True Falsedfとdf_movedを連結します。
列方向へのデータ連結
concat関数を使い、引数に2つのDataFrameをリストにして渡します。axis=1を引数に加えることで列方向への連結となります。
df_merged=pd.concat([df,df_moved],axis=1)
df_merged売上 来客数 売上/来客数 売上指数 売上_High 売上_Low 売上_Mid
date
2023-01-01 69989 51 1372.333333 Mid False False True
2023-01-02 78302 70 1118.600000 Mid False False True
2023-01-03 53671 25 2146.840000 High True False False
2023-01-04 86240 26 3316.923077 High True False False
2023-01-05 74553 89 837.674157 Low False True False
2023-01-06 49224 21 2344.000000 High True False False
2023-01-07 93566 67 1396.507463 Mid False False True
2023-01-08 52820 64 825.312500 Low False True False
2023-01-09 76983 37 2080.621622 High True False False
2023-01-10 33345 60 555.750000 Low False True False
2023-01-11 46629 73 638.753425 Low False True False
2023-01-12 49661 47 1056.617021 Mid False False True
2023-01-13 22210 84 264.404762 Low False True False
2023-01-14 83898 69 1215.913043 Mid False False True
2023-01-15 58561 34 1722.382353 Mid False False True
2023-01-16 16743 68 246.220588 Low False True False
2023-01-17 3682 57 64.596491 Low False True False
2023-01-18 16169 10 1616.900000 Mid False False True
2023-01-19 87110 84 1037.023810 Mid False False True
2023-01-20 74743 70 1067.757143 Mid False False True
2023-01-21 99073 40 2476.825000 High True False False
2023-01-22 80673 41 1967.634146 Mid False False True
2023-01-23 68824 21 3277.333333 High True False False
2023-01-24 48194 31 1554.645161 Mid False False True
2023-01-25 52180 79 660.506329 Low False True False
2023-01-26 93228 74 1259.837838 Mid False False True
2023-01-27 48630 69 704.782609 Low False True False
2023-01-28 15228 87 175.034483 Low False True False
2023-01-29 33949 17 1997.000000 Mid False False True
2023-01-30 39738 50 794.760000 Low False True False行方向へのデータ連結
concat関数を使い、引数に2つのDataFrameをリストにして渡します。axis=0を引数に加えることで行方向への連結となります。
df_merged2=pd.concat([df,df_moved],axis=0)
df_merged2 売上 来客数 売上/来客数 売上指数 売上_High 売上_Low 売上_Mid
date
2023-01-01 69989.0 51.0 1372.333333 Mid NaN NaN NaN
2023-01-02 78302.0 70.0 1118.600000 Mid NaN NaN NaN
2023-01-03 53671.0 25.0 2146.840000 High NaN NaN NaN
2023-01-04 86240.0 26.0 3316.923077 High NaN NaN NaN
2023-01-05 74553.0 89.0 837.674157 Low NaN NaN NaN
2023-01-06 49224.0 21.0 2344.000000 High NaN NaN NaN
2023-01-07 93566.0 67.0 1396.507463 Mid NaN NaN NaN
2023-01-08 52820.0 64.0 825.312500 Low NaN NaN NaN
2023-01-09 76983.0 37.0 2080.621622 High NaN NaN NaN
2023-01-10 33345.0 60.0 555.750000 Low NaN NaN NaN
2023-01-11 46629.0 73.0 638.753425 Low NaN NaN NaN
2023-01-12 49661.0 47.0 1056.617021 Mid NaN NaN NaN
2023-01-13 22210.0 84.0 264.404762 Low NaN NaN NaN
2023-01-14 83898.0 69.0 1215.913043 Mid NaN NaN NaN
2023-01-15 58561.0 34.0 1722.382353 Mid NaN NaN NaN
2023-01-16 16743.0 68.0 246.220588 Low NaN NaN NaN
2023-01-17 3682.0 57.0 64.596491 Low NaN NaN NaN
2023-01-18 16169.0 10.0 1616.900000 Mid NaN NaN NaN
2023-01-19 87110.0 84.0 1037.023810 Mid NaN NaN NaN
2023-01-20 74743.0 70.0 1067.757143 Mid NaN NaN NaN
2023-01-21 99073.0 40.0 2476.825000 High NaN NaN NaN
2023-01-22 80673.0 41.0 1967.634146 Mid NaN NaN NaN
2023-01-23 68824.0 21.0 3277.333333 High NaN NaN NaN
2023-01-24 48194.0 31.0 1554.645161 Mid NaN NaN NaN
2023-01-25 52180.0 79.0 660.506329 Low NaN NaN NaN
2023-01-26 93228.0 74.0 1259.837838 Mid NaN NaN NaN
2023-01-27 48630.0 69.0 704.782609 Low NaN NaN NaN
2023-01-28 15228.0 87.0 175.034483 Low NaN NaN NaN
2023-01-29 33949.0 17.0 1997.000000 Mid NaN NaN NaN
2023-01-30 39738.0 50.0 794.760000 Low NaN NaN NaN
2023-01-01 NaN NaN NaN NaN False False True
2023-01-02 NaN NaN NaN NaN False False True
2023-01-03 NaN NaN NaN NaN True False False
・・・
2023-01-30 NaN NaN NaN NaN False True False統計データの扱い
まずはpickleで保存したデータを読み込みます。
df=pd.read_pickle("C:/data/sales.pickle")
df売上 来客数 売上/来客数 売上指数
date
2023-01-01 69989 51 1372.333333 Mid
2023-01-02 78302 70 1118.600000 Mid
2023-01-03 53671 25 2146.840000 High
2023-01-04 86240 26 3316.923077 High
2023-01-05 74553 89 837.674157 Low
2023-01-06 49224 21 2344.000000 High
2023-01-07 93566 67 1396.507463 Mid
2023-01-08 52820 64 825.312500 Low
2023-01-09 76983 37 2080.621622 High
2023-01-10 33345 60 555.750000 Low
2023-01-11 46629 73 638.753425 Low
2023-01-12 49661 47 1056.617021 Mid
2023-01-13 22210 84 264.404762 Low
2023-01-14 83898 69 1215.913043 Mid
2023-01-15 58561 34 1722.382353 Mid
2023-01-16 16743 68 246.220588 Low
2023-01-17 3682 57 64.596491 Low
2023-01-18 16169 10 1616.900000 Mid
2023-01-19 87110 84 1037.023810 Mid
2023-01-20 74743 70 1067.757143 Mid
2023-01-21 99073 40 2476.825000 High
2023-01-22 80673 41 1967.634146 Mid
2023-01-23 68824 21 3277.333333 High
2023-01-24 48194 31 1554.645161 Mid
2023-01-25 52180 79 660.506329 Low
2023-01-26 93228 74 1259.837838 Mid
2023-01-27 48630 69 704.782609 Low
2023-01-28 15228 87 175.034483 Low
2023-01-29 33949 17 1997.000000 Mid
2023-01-30 39738 50 794.760000 Low
基本統計量
maxメソッドを使って最大値を出力します。
df.loc[:,"売上"].max()99073minメソッドを使って最小値を出力します。
df.loc[:,"売上"].min()3682modeメソッドを使って最頻値を出力します。
df.loc[:,"来客数"].mode()0 21
1 69
2 70
3 84
Name: 来客数, dtype: int64meanメソッドを使って算術平均(平均値)を出力します。
df.loc[:,"来客数"].mean()53.833333333333336medianメソッドを使って中央値を出力します。
df.loc[:,"来客数"].median()58.5stdメソッドを使って標準偏差を出力します。
df.loc[:,"売上"].std()26358.277688749724stdメソッドを使って、母集団の標準偏差を出力する場合は、stdメソッドにddof=0を指定します。(デフォルトはddof=1)
df.loc[:,"売上"].std(ddof=0)25915.249872613615countメソッドを使って件数を出力します。
売上が20000以上のデータの件数を出力します。
df[df.loc[:,"売上"]>=20000].count()売上 26
来客数 26
売上/来客数 26
売上指数 26
dtype: int64要約
describeメソッドを使って、DataFrameの統計量をまとめて出力します。
df.describe() 売上 来客数 売上/来客数
count 30.000000 30.000000 30.000000
mean 56927.200000 53.833333 1326.449656
std 26358.277689 23.294343 844.766729
min 3682.000000 10.000000 64.596491
25% 41460.750000 34.750000 727.276957
50% 53245.500000 58.500000 1167.256522
75% 77972.250000 70.000000 1906.321198
max 99073.000000 89.000000 3316.923077相関関係
カラム間のデータの関係を数値で確認し、相関関係を出力します。
df.corr() 売上 来客数 売上/来客数
売上 1.000000 0.043964 0.518586
来客数 0.043964 1.000000 -0.761210
売上/来客数 0.518586 -0.761210 1.000000散布図行列
Jupyter Notebookの場合、最初に下記マジックコマンドを実行します。
%matplotlib inLine散布図行列を出力する関数をインポートします。
from pandas.plotting import scatter_matrixscatter関数に、引数としてDataFrameを渡すと散布図行列が出力されます。
_ = scatter_matrix(df)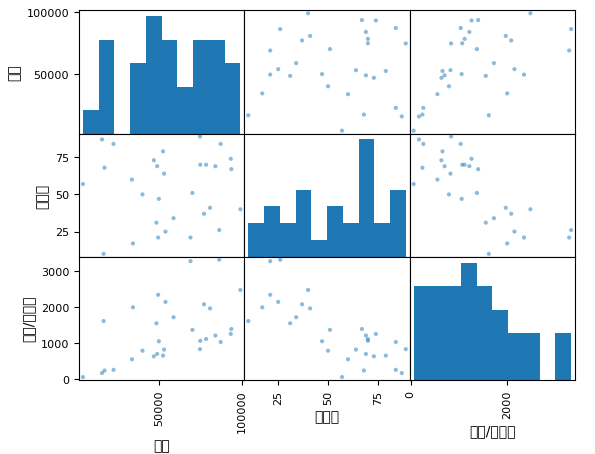
データ変換
機械学習フレームワークによっては、pandasのDataFrameは受け取れないことがあります。
Numpyの配列(ndarray)しか受け付けない場合もあります。
そのため、pandasのDataFrameをNumpyの配列(ndarray)に変換する方法を確認しましょう。
df.loc[:,["売上","来客数"]] 売上 来客数
date
2023-01-01 69989 51
2023-01-02 78302 70
2023-01-03 53671 25
2023-01-04 86240 26
2023-01-05 74553 89
2023-01-06 49224 21
2023-01-07 93566 67
2023-01-08 52820 64
2023-01-09 76983 37
2023-01-10 33345 60
2023-01-11 46629 73
2023-01-12 49661 47
2023-01-13 22210 84
2023-01-14 83898 69
2023-01-15 58561 34
2023-01-16 16743 68
2023-01-17 3682 57
2023-01-18 16169 10
2023-01-19 87110 84
2023-01-20 74743 70
2023-01-21 99073 40
2023-01-22 80673 41
2023-01-23 68824 21
2023-01-24 48194 31
2023-01-25 52180 79
2023-01-26 93228 74
2023-01-27 48630 69
2023-01-28 15228 87
2023-01-29 33949 17
2023-01-30 39738 50上記のpandasのDataFrameをNumpy(ndaaray)に変換します。values属性を使用します。
df.loc[:,["売上","来客数"]].valuesarray([[69989, 51],
[78302, 70],
[53671, 25],
[86240, 26],
[74553, 89],
[49224, 21],
[93566, 67],
[52820, 64],
[76983, 37],
[33345, 60],
[46629, 73],
[49661, 47],
[22210, 84],
[83898, 69],
[58561, 34],
[16743, 68],
[ 3682, 57],
[16169, 10],
[87110, 84],
[74743, 70],
[99073, 40],
[80673, 41],
[68824, 21],
[48194, 31],
[52180, 79],
[93228, 74],
[48630, 69],
[15228, 87],
[33949, 17],
[39738, 50]], dtype=int64)
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント